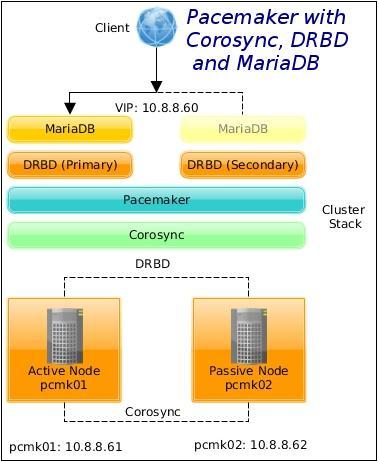
We are going to build a two-node active/passive MariaDB HA cluster using Pacemaker and Corosync.
Before We Begin
We will use MariaDB, which is a binary drop in replacement for MySQL. MySQL is no longer in CentOS’s repositories and MariaDB has become the default database system offered.
MariaDB claims to have a lot of new options, extension, storage engines and bug fixes that are not in MySQL. Check this page https://mariadb.com/kb/en/mariadb/mariadb-vs-mysql-compatibility/ for more info about the MariaDB.
No shared storage will be required. At any point in time, the MariaDB service will be active on one cluster node.
The convention followed in the article is that [ALL] # denotes a command that needs to be run on all cluster nodes.
Software
Software used in this article:
- CentOS Linux release 7.2.1511 (Core)
- kernel-3.10.0-327.4.4.el7
- pacemaker-1.1.13
- corosync-2.3.4
- pcs-0.9.143
- resource-agents-3.9.5
- drbd-8.4 (kmod-drbd84-8.4.7)
- MariaDB 5.5.44
Networking, Firewall and SELinux Configuration
We have two CentOS 7 virtual machines on VirtualBox, named pcmk01 and pcmk02.
Networking
The following networks will be used:
- 10.8.8.0/24 – LAN with access to the Internet (host-only adapter),
- 172.16.21.0/24 – non-routable cluster heartbeat vlan for Corosync (internal network adapter),
- 172.16.22.0/24 – non-routable cluster heartbeat vlan for DRBD (internal network adapter).
Hostnames and IPs as defined in /etc/hosts file:
10.8.8.60 pcmkvip 10.8.8.61 pcmk01 10.8.8.62 pcmk02 172.16.21.11 pcmk01-cr 172.16.21.12 pcmk02-cr 172.16.22.11 pcmk01-drbd 172.16.22.12 pcmk02-drbd
We have set the following hostnames:
[pcmk01]# hostnamectl set-hostname pcmk01 [pcmk02]# hostnamectl set-hostname pcmk02
A simplified network configuration can be seen below.
Network configuration for the first node can be seen below, it is the same for the second node except the IPs which are specified above.
[pcmk01]# cat /etc/sysconfig/network-scripts/ifcfg-enp0s8
#Corosync ring0
NAME="enp0s8"
DEVICE="enp0s8"
IPADDR="172.16.21.11"
PREFIX="24"
TYPE="Ethernet"
IPV4_FAILURE_FATAL="yes"
IPV6INIT="no"
DEFROUTE="no"
PEERDNS="no"
PEERROUTES="no"
ONBOOT="yes"
[pcmk01]# cat /etc/sysconfig/network-scripts/ifcfg-enp0s9
#DRBD
NAME="enp0s9"
DEVICE="enp0s9"
IPADDR="172.16.22.11"
PREFIX="24"
TYPE="Ethernet"
IPV4_FAILURE_FATAL="yes"
IPV6INIT="no"
DEFROUTE="no"
PEERDNS="no"
PEERROUTES="no"
ONBOOT="yes"
[pcmk01]# cat /etc/sysconfig/network-scripts/ifcfg-enp0s17
#LAN
NAME="enp0s17"
DEVICE="enp0s17"
IPADDR="10.8.8.61"
PREFIX="24"
GATEWAY="10.8.8.1"
DNS1="8.8.8.8"
DNS2="8.8.4.4"
TYPE="Ethernet"
IPV4_FAILURE_FATAL="yes"
IPV6INIT="no"
DEFROUTE="yes"
PEERDNS="yes"
ONBOOT="yes"
Iptables
This article uses Iptables firewall. Note that CentOS 7 utilises FirewallD as the default firewall management tool.
We replaced FirewallD service with Iptables:
[ALL]# systemctl stop firewalld.service [ALL]# systemctl mask firewalld.service [ALL]# systemctl daemon-reload [ALL]# yum install -y iptables-services [ALL]# systemctl enable iptables.service [ALL]# service iptables save
These are the iptables firewall rules that we have in use:
# iptables -S -P INPUT ACCEPT -P FORWARD ACCEPT -P OUTPUT ACCEPT -A INPUT -p icmp -j ACCEPT -A INPUT -i lo -j ACCEPT -A INPUT -s 10.8.8.0/24 -p tcp -m tcp --dport 22 -m state --state NEW -j ACCEPT -A INPUT -s 172.16.21.0/24 -d 172.16.21.0/24 -m comment --comment Corosync -j ACCEPT -A INPUT -s 172.16.22.0/24 -d 172.16.22.0/24 -m comment --comment DRBD -j ACCEPT -A INPUT -s 10.8.8.0/24 -p tcp -m tcp --dport 3306 -m state --state NEW -j ACCEPT -A INPUT -p udp -m multiport --dports 67,68 -m state --state NEW -j ACCEPT -A INPUT -p udp -m multiport --dports 137,138,139,445 -j DROP -A INPUT -m state --state RELATED,ESTABLISHED -j ACCEPT -A INPUT -j LOG --log-prefix "iptables_input " -A INPUT -j DROP
We have also disabled IPv6, open /etc/sysctl.conf for editing and place the following:
net.ipv6.conf.all.disable_ipv6 = 1 net.ipv6.conf.default.disable_ipv6 = 1
[ALL]# sysctl -p
SELinux
SELinux is set to enforcing mode.
Install Pacemaker and Corosync
[ALL]# yum install -y pcs
The pcs will install pacemaker, corosync and resource-agents as dependencies.
For SELinux management:
[ALL]# yum install -y policycoreutils-python
In RHEL 7, we have to set up a password for the pcs administration account named hacluster:
[ALL]# echo "passwd" | passwd hacluster --stdin
Start and enable the service:
[ALL]# systemctl start pcsd.service [ALL]# systemctl enable pcsd.service
Configure Corosync
Authenticate as the hacluster user. Authorisation tokens are stored in the file /var/lib/pcsd/tokens.
[pcmk01]# pcs cluster auth pcmk01-cr pcmk02-cr -u hacluster -p passwd pcmk01-cr: Authorized pcmk02-cr: Authorized
Generate and synchronise the Corosync configuration.
[pcmk01]# pcs cluster setup --name mysql_cluster pcmk01-cr pcmk02-cr
Start the cluster on all nodes:
[pcmk01]# pcs cluster start --all
Install DRBD and MariaDB
DRBD Installation
DRBD refers to block devices designed as a building block to form high availability clusters. This is done by mirroring a whole block device via an assigned network. DRBD can be understood as network based RAID-1.
Import the ELRepo package signing key, enable the repository and install the DRBD kernel module with utilities:
[ALL]# rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org [ALL]# rpm -Uvh http://www.elrepo.org/elrepo-release-7.0-2.el7.elrepo.noarch.rpm [ALL]# yum install -y kmod-drbd84 drbd84-utils
To avoid issues with SELinux, for the time being, we are going to exempt DRBD processes from SELinux control:
[ALL]# semanage permissive -a drbd_t
LVM Volume for DRBD
Create a new 1GB logical volume for DRBD:
[pcmk01]# vgs VG #PV #LV #SN Attr VSize VFree vg_centos7 1 3 0 wz--n- 63.21g 45.97g
[ALL]# lvcreate --name lv_drbd --size 1024M vg_centos7
Configure DRBD
Configure DRBD, use single-primary mode with replication protocol C.
[ALL]# cat << EOL >/etc/drbd.d/mysql01.res
resource mysql01 {
protocol C;
meta-disk internal;
device /dev/drbd0;
disk /dev/vg_centos7/lv_drbd;
handlers {
split-brain "/usr/lib/drbd/notify-split-brain.sh root";
}
net {
allow-two-primaries no;
after-sb-0pri discard-zero-changes;
after-sb-1pri discard-secondary;
after-sb-2pri disconnect;
rr-conflict disconnect;
}
disk {
on-io-error detach;
}
syncer {
verify-alg sha1;
}
on pcmk01 {
address 172.16.22.11:7789;
}
on pcmk02 {
address 172.16.22.12:7789;
}
}
EOL
We have a resource named mysql01 which uses /dev/vg_centos7/lv_drbd as the lower-level device, and is configured with internal meta data.
The resource uses TCP port 7789 for its network connections, and binds to the IP addresses 172.16.22.11 and 172.16.22.12, respectively.
If case we run into problems, we have to ensure that a TCP 7789 port is open on a firewall for the DRBD interface and that the resource name matches the file name.
Create the local metadata for the DRBD resource:
[ALL]# drbdadm create-md mysql01
Ensuring that a DRBD kernel module is loaded, bring up the DRBD resource:
[ALL]# drbdadm up mysql01
For data consistency, tell DRBD which node should be considered to have the correct data (can be run on any node as both have garbage at this point):
[pcmk01]# drbdadm primary --force mysql01
Observe the sync:
[pcmk01]# drbd-overview 0:mysql01/0 SyncSource Primary/Secondary UpToDate/Inconsistent [=>..................] sync'ed: 11.8% (926656/1048508)K
Create a filesystem on the DRBD device and tune as required:
[pcmk01]# mkfs.ext4 -m 0 -L drbd /dev/drbd0
[pcmk01]# tune2fs -c 30 -i 180d /dev/drbd0
Mount the disk, we will populate it with MariaDB content shortly:
[pcmk01]# mount /dev/drbd0 /mnt
MariaDB Installation
[ALL]# yum install -y mariadb-server mariadb
Ensure the MariaDB service is disabled, as it will managed by pacemaker:
[ALL]# systemctl disable mariadb.service
Now start the MariaDB service manually on one of the cluster nodes:
[pcmk01]# systemctl start mariadb
We can install a fresh MariaDB database with the mysql_install_db command:
[pcmk01]# mysql_install_db --datadir=/mnt --user=mysql
Run secure installation:
[pcmk01]# mysql_secure_installation
We need to give the same SELinux policy as the MariaDB datadir. The mysqld policy stores data with multiple different file context types under the /var/lib/mysql directory. If we want to store the data in a different directory, we can use the semanage command to add file context.
[pcmk01]# semanage fcontext -a -t mysqld_db_t "/mnt(/.*)?" [pcmk01]# restorecon -Rv /mnt
Please be advised that changes made with the chcon command do not survive a file system relabel, or the execution of the restorecon command. Always use semanage.
At this point our preparation is complete, we can unmount the temporarily mounted filesystem and stop the MariaDB service:
[pcmk01]# umount /mnt
[pcmk01]# systemctl stop mariadb
Last thing to do, we have to put some very basic my.cnf configuration:
[ALL]# cat << EOL > /etc/my.cnf [mysqld] symbolic-links=0 bind_address = 0.0.0.0 datadir = /var/lib/mysql pid_file = /var/run/mariadb/mysqld.pid socket = /var/run/mariadb/mysqld.sock [mysqld_safe] bind_address = 0.0.0.0 datadir = /var/lib/mysql pid_file = /var/run/mariadb/mysqld.pid socket = /var/run/mariadb/mysqld.sock !includedir /etc/my.cnf.d EOL
Configure Pacemaker Cluster
We want the configuration logic and ordering to be as below:
- Start: mysql_fs01 -> mysql_service01 -> mysql_VIP01,
- Stop: mysql_VIP01 -> mysql_service01 -> mysql_fs01.
Where mysql_fs01 is the filesystem resource, mysql_service01 is the mysqld service resource, and mysql_VIP01 is the floating virtual IP 10.8.8.60.
One handy feature pcs has is the ability to queue up several changes into a file and commit those changes atomically. To do this, we start by populating the file with the current raw XML config from the CIB:
[pcmk01]# pcs cluster cib clust_cfg
Disable STONITH. Be advised that a node level fencing configuration depends heavily on environment. You can check this page for Pacemaker STONITH device configuration on VMware.
[pcmk01]# pcs -f clust_cfg property set stonith-enabled=false
Set quorum policy to ignore:
[pcmk01]# pcs -f clust_cfg property set no-quorum-policy=ignore
Prevent the resources from moving after recovery as it usually increases downtime:
[pcmk01]# pcs -f clust_cfg resource defaults resource-stickiness=200
Create a cluster resource named mysql_data01 for the DRBD device, and an additional clone resource MySQLClone01 to allow the resource to run on both cluster nodes at the same time:
[pcmk01]# pcs -f clust_cfg resource create mysql_data01 ocf:linbit:drbd \ drbd_resource=mysql01 \ op monitor interval=30s
[pcmk01]# pcs -f clust_cfg resource master MySQLClone01 mysql_data01 \ master-max=1 master-node-max=1 \ clone-max=2 clone-node-max=1 \ notify=true
Note the meta variables used:
master-max: how many copies of the resource can be promoted to master status,
master-node-max: how many copies of the resource can be promoted to master status on a single node,
clone-max: how many copies of the resource to start. Defaults to the number of nodes in the cluster,
clone-node-max: how many copies of the resource can be started on a single node,
notify: when stopping or starting a copy of the clone, tell all the other copies beforehand and when the action was successful.
Create a cluster resource named mysql_fs01 for the filesystem. Tell the cluster that the clone resource MySQLClone01 must be run on the same node as the filesystem resource, and that the clone resource must be started before the filesystem resource.
[pcmk01]# pcs -f clust_cfg resource create mysql_fs01 Filesystem \ device="/dev/drbd0" \ directory="/var/lib/mysql" \ fstype="ext4"
[pcmk01]# pcs -f clust_cfg constraint colocation add mysql_fs01 with MySQLClone01 \ INFINITY with-rsc-role=Master
[pcmk01]# pcs -f clust_cfg constraint order promote MySQLClone01 then start mysql_fs01
Create a cluster resource named mysql_service01 for the MariaDB service. Tell the cluster that the MariaDB service must be run on the same node as the mysql_fs01 filesystem resource, and that the filesystem resource must be started first.
[pcmk01]# pcs -f clust_cfg resource create mysql_service01 ocf:heartbeat:mysql \ binary="/usr/bin/mysqld_safe" \ config="/etc/my.cnf" \ datadir="/var/lib/mysql" \ pid="/var/lib/mysql/mysql.pid" \ socket="/var/lib/mysql/mysql.sock" \ additional_parameters="--bind-address=0.0.0.0" \ op start timeout=60s \ op stop timeout=60s \ op monitor interval=20s timeout=30s
[pcmk01]# pcs -f clust_cfg constraint colocation add mysql_service01 with mysql_fs01 INFINITY
[pcmk01]# pcs -f clust_cfg constraint order mysql_fs01 then mysql_service01
Finally, create a cluster resource named mysql_VIP01 for the virtual IP 10.8.8.60.
[pcmk01]# pcs -f clust_cfg resource create mysql_VIP01 ocf:heartbeat:IPaddr2 \ ip=10.8.8.60 cidr_netmask=32 \ op monitor interval=30s
Why to use IPaddr2 and not IPaddr:
- IPaddr – manages virtual IPv4 addresses (portable version),
- IPaddr2 – manages virtual IPv4 addresses (Linux specific version).
The virtual IP mysql_VIP01 resource must be run on the same node as the MariaDB resource, naturally, and must be started the last. This is to ensure that all other resources are already started before we can connect to the virtual IP.
[pcmk01]# pcs -f clust_cfg constraint colocation add mysql_VIP01 with mysql_service01 INFINITY
[pcmk01]# pcs -f clust_cfg constraint order mysql_service01 then mysql_VIP01
Let us check the configuration:
[pcmk01]# pcs -f clust_cfg constraint Location Constraints: Ordering Constraints: promote MySQLClone01 then start mysql_fs01 (kind:Mandatory) start mysql_fs01 then start mysql_service01 (kind:Mandatory) start mysql_service01 then start mysql_VIP01 (kind:Mandatory) Colocation Constraints: mysql_fs01 with MySQLClone01 (score:INFINITY) (with-rsc-role:Master) mysql_service01 with mysql_fs01 (score:INFINITY) mysql_VIP01 with mysql_service01 (score:INFINITY)
[pcmk01]# pcs -f clust_cfg resource show
Master/Slave Set: MySQLClone01 [mysql_data01]
Stopped: [ pcmk01-cr pcmk02-cr ]
mysql_fs01 (ocf::heartbeat:Filesystem): Stopped
mysql_service01 (ocf::heartbeat:mysql): Stopped
mysql_VIP01 (ocf::heartbeat:IPaddr2): Stopped
We can commit changes now and check cluster status:
[pcmk01]# pcs cluster cib-push clust_cfg
[pcmk01]# pcs status
[...]
Online: [ pcmk01-cr pcmk02-cr ]
Full list of resources:
Master/Slave Set: MySQLClone01 [mysql_data01]
Masters: [ pcmk01-cr ]
Stopped: [ pcmk02-cr ]
mysql_fs01 (ocf::heartbeat:Filesystem): Started pcmk01-cr
mysql_service01 (ocf::heartbeat:mysql): Started pcmk01-cr
mysql_VIP01 (ocf::heartbeat:IPaddr2): Started pcmk01-cr
[...]
Once the configuration has been committed, Pacemaker will:
- Start DRBD on both cluster nodes,
- Select one node for promotion to the DRBD Primary role,
- Mount the filesystem, configure the cluster IP address, and start the MariaDB server on the same node,
- Commence resource monitoring
We can test the MariaDB service by telneting into the virtual IP 10.8.8.60 on a TCP por 3306:
# telnet 10.8.8.60 3306 Trying 10.8.8.60... Connected to 10.8.8.60. Escape character is '^]'. Host 'puppet.hl.local' is not allowed to connect to this MariaDB serverConnection closed by foreign host.
References
http://www.linux-ha.org/wiki/Resource_agents
http://www.linux-ha.org/doc/man-pages/re-ra-mysql.html
http://albertolarripa.com/2012/05/13/install-configure-mysql-cluster/
Best article I’ve seen yet on this topic. Clear, concise and completely accurate.
Thanks!
Thanks. I have to agree with this one, not that many constructive articles for CentOS 7 on the net. I had some troubles migrating Pacemaker from RHEL 6 to RHEL 7, therefore putting it online seemed like a good idea.
Hi Thomas,
Excelent post. I haven’t tried jet but doesn’t seems hard to follow.
Why did you choose to replicate databases by files and not using mysql replication implementation? Do you know if is slower than syncing by the classic method?
Thanks, and congratulations for the guide.
Hi Felipe, Thanks for your feedback.
I’m used to SAN based high availability solutions with active-passive management software and it was natural for me to use such approach for MySQL. I was migrating from cman (CentOS 6) to pcs (CentOS 7) in this particular case.
Thanks for the article. Very nice!!!
Welcome.
at drbdadm create-md mysql01
I get an error: ‘mysql01’ not defined in your config (for this host).
Check the DRBD config, ensure you got the DRBD resource name right, also check hostnames of your DRBD nodes – they need to match with the ones defined in the config.
Hi,
i am currently working on a school project where im using PCS cluster. i managed to get it ip and running with my apache webservers. now im working on mariadb cluster. most of the config is the same and for the additional info i used your guide. the only thing that is different is that im using a MS iscsi target server for the shared directory. i managed to get it all up and running. both nodes have mariadb and the exact same. the parameters in the mysql_service resource are all specified to the shared storage location (/mnt/iscsi_share) exept the binary and config. i dident touch those.
the cluster is now working only on 1 node. altough it has exact the same config file. ik getting the following error code:
mysql_service_start_0 on linux06 ‘unknown error’ (1): call=20, status=complete, exitreason=’MySQL server failed to start (pid=3307) (rc=0), please check your installation’,
last-rc-change=’Thu Jun 2 15:05:18 2016′, queued=0ms, exec=4969ms
do you have any idea whear i need to start looking or what may couse this problem. the database on linux 5 works and i can reach it and modify it.
i hope you can understand my problem with this rubish english grammer :)
Do you have SELinux enabled? If so, can you post me the output of the following command:
What filesystem do you use on
/mnt/iscsi_share? Is it mounted on all cluster nodes?What operating system do run the cluster on?
Hi Tomas,
Sorry for the late reply but my deadline is closing in and im very busy with the documentation. I managed to get it up and running correctly. im using ext.4 and run it on CentOS 7. The error had something to do with the constraints. I followed your guide on this. the db worked but was not able to shutdown. so i decided to remove them. Now the cluster worked like i said in the previous comment. Later i decided to give the constraints another try. I had one combining stonith device and filesystem. this one was giving me the problems. Now my cluster works with the following constraints.
thanks for your help and your guide! i would not have managed to make ik without it!
I’m glad you managed to sort it out.
I see that you have a colocation constraint for the virtual_ip, but there is no ordering constraint for it. You should add one to ensure that all MySQL resources are started before you can connect to the virtual IP.
Hi Tomas,
Many thanks for your article. Currently, I am trying to deploy it through a two servers in VirtualBox. I have a question regarding the interfaces. For each IP address ( 10.8.8.61, 172.16.21.11 and 172.16.22.11 ), do you have a multiple interfaces in your servers or are they virtual interface? I would like to know which interface do you have to create it through vagrant.
BR
I do have multiple host-only interfaces for each IP address.
When I create the interfaces ifcfg-enp0s8, ifcfg-enp0s9 and ifcfg-enp0s17 in a host-only interface of VirtualMachine it cannot auth. Besides, I only see eth interfaces as older mode.
My apologies, the LAN is on a host-only adapter, but both non-routable cluster heartbeat vlans use internal network adapters. I’ve updated the article.
What OS do you use? CentOS 7 uses so-called predictable network interface names by default, therefore the actual interface names on your system may be different compared to the ones mentioned in the article. If you want to go back to traditional interface naming scheme (“eth0”, “eth1” etc), you can do so in udev.
I am also using CentOS 7. The issue that I have found that I was creating a VM with just one interface and when I created the enp interfaces communication between VMs wasn’t properly. So, auth step doesn’t work and I had to provision three interface for each network. After, I provisioned three interfaces and it create eth interfaces and communication between VMs was properly.
Do you advice use the same network for the communication of pcmk nodes?
You can use a single network interface for everything (LAN, Corosync and DRBD) if you wish, for testing it hardly matters.
For production, you likely want to have redundant interfaces (teamed/bonded LAN, two Corosync rings etc).
I really love this article! Hard to find good info on MySQL, everybody has Apache+DRBD, but this is the beezneez!
A nice trick for CentOS 7 to make eno/enp back to eth0 I found on NerdVittles…
I wanted to ask, if you have or could create an article for CentOS 6 as you mentioned that you used to use that. I am building HA VoIP Servers and currently all the pre-packaged distros are on CentOS 6 and I can only get HA working on CentOS 7 with pcsd lol, its been a nightmare figuring out if I want to build VoIP by hand on 7 or stuggle with HA on CentOS6 ontop of a custom Distro. After reading this, I am leaning towards building a custom server with PIAF/IncrediblePBX + Linux HA. Thanks!
Glad you found it helpful. I’m afraid I have no plans to go back to CentOS 6.
Not sure if it helps you, but cluster stack on CentOS 6 is based on cman, I may be wrong, but I think that crmsh is no longer available on RHEL (thus no longer available on CentOS), but pcs is fully supported starting CentOS 6.5.
CentOS 6 has been around for quite some time now, I think that you’ll be able to find dozens of articles covering HA setup online.
I think I found a mistake/problem in the guide…
NOT
Bonus :
Just organizes the output of pcs in a nice OU.
Was wondering if your interested/available for some paid support helping me get my system running, I am having some trouble, but I am going to create a new test bed this weekend and follow your guide to the letter and hope that works.
Master/Slave Set: MySQLClone01 [mysql_data01] mysql_data01 (ocf::linbit:drbd): FAILED node2 (unmanaged) mysql_data01 (ocf::linbit:drbd): FAILED node1 (unmanaged) Resource Group: SQL-Group mysqld (ocf::heartbeat:mysql): Stopped mysql_fs01 (ocf::heartbeat:Filesystem): Stopped mysql_data01_stop_0 on node2 'not configured' (6): call=29, status=complete, last-rc-change='Wed Jun 8 21:27:08 2016', queued=1ms, exec=15ms (same thing for node1)is where I am at right now… I am literally just starting my career and got the go-ahead to build a HA Voip Server @ work and have been struggling getting MySQL Services moved over to DRBD/PaceMaker.
Thanks for the great guide again!
Not a mistake as such as I actually use a mysqld named folder under
/var/run, however, I forgot to include a step for creating it. I updated the article, thanks for spotting. Just to make it clear, the folder that’s created by default is/var/run/mariadb/.With regards to resource groups, you’re right, grouping resources can simplify Pacemaker configuration, as in this article, but it’s not mandatory to get things working. You simply need to ensure that resources run on the same host by creating a colocation constraint with a score of INFINITY.
Looking at the error you got above, it seems like your DRBD may not be configured properly.
As for paid support, I’m usually open-minded, however, as a rule of thumb I only tend to provide support for systems that I build myself. Supporting something that was created by other people (however good or bad it might be) isn’t my cup of tea really as more often than not, such systems prove to be built in a haphazard way. Disclaimer alert – don’t take it for granted, it’s just my experience talking.
I seem to be stuck, this time I am following you guide 99% (Changed IP’s and hostnames)
[root@node1 ~]# mysql_install_db –datadir=/mnt –user=mysql
chown: changing ownership of ‘/mnt’: Read-only file system
Cannot change ownership of the database directories to the ‘mysql’
user. Check that you have the necessary permissions and try again.
I never did hear from you, but I am not really looking for ongoing support, just a some money to help troubleshoot my configs in a VM. (I am starting to wonder if its go something to do with the VM part of the equation, since sdb1 is virtual, also its only 2GB, but I don’t think that should matter…)
I just wanted to say I got it! As a thank you I will make a donation!
4 others who may have the same issues I was.
My issues :
1. I was started with a preformatted disk, start with a brand new disk and use fdisk
2. My VIP needed to have nic=eth0 because I didn’t follow the IP’s/Nics part of this guide
Good to know you finally managed to make it work.
Hi Tomas,
I have the same issue than @FreeSoftwareServers regarding with the resource of mysql_data01. I configured properly DRBD because I got in first place the status SyncSource and after when it finishes the synchronization is Completed:
# drbd-overview
0:mysql01/0 SyncSource Primary/Secondary UpToDate/Inconsistent
[====>……………] sync’ed: 26.3% (242600/327632)K
# drbd-overview
0:mysql01/0 Connected Primary/Secondary UpToDate/UpToDate
It seems that drbd works properly but I created the mysql_data01 as you show and after check the status. It fails despite the status in the monitor is complete:
mysql_data01 (ocf::linbit:drbd): FAILED (unmanaged)[ pcmk02-cr pcmk01-cr ]
Failed Actions:
* mysql_data01_stop_0 on pcmk02-cr ‘not configured’ (6): call=6, status=complete, exitreason=’none’,
last-rc-change=’Mon Jun 27 11:43:17 2016′, queued=0ms, exec=198ms
* mysql_data01_stop_0 on pcmk01-cr ‘not configured’ (6): call=6, status=complete, exitreason=’none’,
last-rc-change=’Mon Jun 27 11:43:17 2016′, queued=0ms, exec=117ms
I have no errors with filesystem resource. Currently, I am using two vagrant machines to test it. Do you know wich kind of issue it could be? Because the status seems ok but pacemaker perform it like an error.
Many thanks for your help in advance,
BR
What’s the value of drbd_resource that you passed to the Pacemaker when creating the cluster resource named mysql_data01?
#pcs resource create mysql_data01 ocf:linbit:drbd drbd_resource=mysql01 op monitor interval=30s
That looks good to me. What does pacemaker log say?
The log is located in /var/log/cluster/corosync.log. Sorry for the stuff:
Jun 27 14:30:06 [2053] pcmk01 crmd: error: crm_abort: pcmkRegisterNode: Triggered assert at xml.c:594 : node->type == XML_ELEMENT_NODE
Jun 27 14:30:06 [2053] pcmk01 crmd: notice: process_lrm_event: Operation mysql_data01_monitor_0: not configured (node=pcmk01-cr, call=5, rc=6, cib-update=49, confirmed=true)
Jun 27 14:30:06 [2048] pcmk01 cib: info: cib_process_request: Forwarding cib_modify operation for section status to master (origin=local/crmd/49)
Jun 27 14:30:06 [2048] pcmk01 cib: info: cib_perform_op: Diff: — 0.9.0 2
Jun 27 14:30:06 [2048] pcmk01 cib: info: cib_perform_op: Diff: +++ 0.9.1 (null)
Jun 27 14:30:06 [2048] pcmk01 cib: info: cib_perform_op: + /cib: @num_updates=1
Jun 27 14:30:06 [2048] pcmk01 cib: info: cib_perform_op: + /cib/status/node_state[@id=’1′]: @crm-debug-origin=do_update_resource
Jun 27 14:30:06 [2048] pcmk01 cib: info: cib_perform_op: ++ /cib/status/node_state[@id=’1′]/lrm[@id=’1′]/lrm_resources:
Jun 27 14:30:06 [2048] pcmk01 cib: info: cib_perform_op: ++ <lrm_rsc_op id="mysql_data01_last_failure_0" operation_key="mysql_data01_monitor_0" operation="monitor" crm-debug-origin="do_update_resource" crm_feature_set="3.0.10" transition-key="4:5:7:0e367aab-5184-4c54-87da-0562471c2635" transition-magic="0:6;4:5:7:0e367aab-5184-4c54-87da-0562471c2635" on_node="pcmk01-cr" call-id="5" rc-code="6" op-status="0" interval="0" last-run="146
Jun 27 14:30:06 [2048] pcmk01 cib: info: cib_perform_op: ++ <lrm_rsc_op id="mysql_data01_last_0" operation_key="mysql_data01_monitor_0" operation="monitor" crm-debug-origin="do_update_resource" crm_feature_set="3.0.10" transition-key="4:5:7:0e367aab-5184-4c54-87da-0562471c2635" transition-magic="0:6;4:5:7:0e367aab-5184-4c54-87da-0562471c2635" on_node="pcmk01-cr" call-id="5" rc-code="6" op-status="0" interval="0" last-run="1467037806"
Jun 27 14:30:06 [2048] pcmk01 cib: info: cib_perform_op: ++
Jun 27 14:30:06 [2048] pcmk01 cib: info: cib_process_request: Completed cib_modify operation for section status: OK (rc=0, origin=pcmk01-cr/crmd/49, version=0.9.1)
Jun 27 14:30:06 [2053] pcmk01 crmd: warning: status_from_rc: Action 4 (mysql_data01_monitor_0) on pcmk01-cr failed (target: 7 vs. rc: 6): Error
Jun 27 14:30:06 [2053] pcmk01 crmd: notice: abort_transition_graph: Transition aborted by mysql_data01_monitor_0 ‘create’ on pcmk01-cr: Event failed (magic=0:6;4:5:7:0e367aab-5184-4c54-87da-0562471c2635, cib=0.9.1, source=match_graph_event:381, 0)
Jun 27 14:30:06 [2053] pcmk01 crmd: info: match_graph_event: Action mysql_data01_monitor_0 (4) confirmed on pcmk01-cr (rc=6)
Jun 27 14:30:06 [2053] pcmk01 crmd: info: process_graph_event: Detected action (5.4) mysql_data01_monitor_0.5=not configured: failed
Jun 27 14:30:06 [2053] pcmk01 crmd: warning: status_from_rc: Action 4 (mysql_data01_monitor_0) on pcmk01-cr failed (target: 7 vs. rc: 6): Error
Jun 27 14:30:06 [2053] pcmk01 crmd: info: abort_transition_graph: Transition aborted by mysql_data01_monitor_0 ‘create’ on pcmk01-cr: Event failed (magic=0:6;4:5:7:0e367aab-5184-4c54-87da-0562471c2635, cib=0.9.1, source=match_graph_event:381, 0)
Jun 27 14:30:06 [2053] pcmk01 crmd: info: match_graph_event: Action mysql_data01_monitor_0 (4) confirmed on pcmk01-cr (rc=6)
Jun 27 14:30:06 [2053] pcmk01 crmd: info: process_graph_event: Detected action (5.4) mysql_data01_monitor_0.5=not configured: failed
Jun 27 14:30:06 [2053] pcmk01 crmd: notice: te_rsc_command: Initiating action 3: probe_complete probe_complete-pcmk01-cr on pcmk01-cr (local) – no waiting
Jun 27 14:30:06 [2053] pcmk01 crmd: info: te_rsc_command: Action 3 confirmed – no wait
Jun 27 14:30:06 [2048] pcmk01 cib: info: cib_perform_op: Diff: — 0.9.1 2
Jun 27 14:30:06 [2048] pcmk01 cib: info: cib_perform_op: Diff: +++ 0.9.2 (null)
Jun 27 14:30:06 [2048] pcmk01 cib: info: cib_perform_op: + /cib: @num_updates=2
Jun 27 14:30:06 [2048] pcmk01 cib: info: cib_perform_op: + /cib/status/node_state[@id=’2′]: @crm-debug-origin=do_update_resource
Jun 27 14:30:06 [2048] pcmk01 cib: info: cib_perform_op: ++ /cib/status/node_state[@id=’2′]/lrm[@id=’2′]/lrm_resources:
Jun 27 14:30:06 [2048] pcmk01 cib: info: cib_perform_op: ++ <lrm_rsc_op id="mysql_data01_last_failure_0" operation_key="mysql_data01_monitor_0" operation="monitor" crm-debug-origin="do_update_resource" crm_feature_set="3.0.10" transition-key="6:5:7:0e367aab-5184-4c54-87da-0562471c2635" transition-magic="0:6;6:5:7:0e367aab-5184-4c54-87da-0562471c2635" on_node="pcmk02-cr" call-id="5" rc-code="6" op-status="0" interval="0" last-run="146
Jun 27 14:30:06 [2048] pcmk01 cib: info: cib_perform_op: ++ <lrm_rsc_op id="mysql_data01_last_0" operation_key="mysql_data01_monitor_0" operation="monitor" crm-debug-origin="do_update_resource" crm_feature_set="3.0.10" transition-key="6:5:7:0e367aab-5184-4c54-87da-0562471c2635" transition-magic="0:6;6:5:7:0e367aab-5184-4c54-87da-0562471c2635" on_node="pcmk02-cr" call-id="5" rc-code="6" op-status="0" interval="0" last-run="1467037806"
Jun 27 14:30:06 [2048] pcmk01 cib: info: cib_perform_op: ++
Jun 27 14:30:06 [2048] pcmk01 cib: info: cib_process_request: Completed cib_modify operation for section status: OK (rc=0, origin=pcmk02-cr/crmd/16, version=0.9.2)
Jun 27 14:30:06 [2053] pcmk01 crmd: warning: status_from_rc: Action 6 (mysql_data01_monitor_0) on pcmk02-cr failed (target: 7 vs. rc: 6): Error
Jun 27 14:30:06 [2053] pcmk01 crmd: info: abort_transition_graph: Transition aborted by mysql_data01_monitor_0 ‘create’ on pcmk02-cr: Event failed (magic=0:6;6:5:7:0e367aab-5184-4c54-87da-0562471c2635, cib=0.9.2, source=match_graph_event:381, 0)
Jun 27 14:30:06 [2053] pcmk01 crmd: info: match_graph_event: Action mysql_data01_monitor_0 (6) confirmed on pcmk02-cr (rc=6)
Jun 27 14:30:06 [2053] pcmk01 crmd: info: process_graph_event: Detected action (5.6) mysql_data01_monitor_0.5=not configured: failed
Jun 27 14:30:06 [2053] pcmk01 crmd: warning: status_from_rc: Action 6 (mysql_data01_monitor_0) on pcmk02-cr failed (target: 7 vs. rc: 6): Error
Jun 27 14:30:06 [2053] pcmk01 crmd: info: abort_transition_graph: Transition aborted by mysql_data01_monitor_0 ‘create’ on pcmk02-cr: Event failed (magic=0:6;6:5:7:0e367aab-5184-4c54-87da-0562471c2635, cib=0.9.2, source=match_graph_event:381, 0)
Jun 27 14:30:06 [2053] pcmk01 crmd: info: match_graph_event: Action mysql_data01_monitor_0 (6) confirmed on pcmk02-cr (rc=6)
Jun 27 14:30:06 [2053] pcmk01 crmd: info: process_graph_event: Detected action (5.6) mysql_data01_monitor_0.5=not configured: failed
Jun 27 14:30:06 [2053] pcmk01 crmd: notice: te_rsc_command: Initiating action 5: probe_complete probe_complete-pcmk02-cr on pcmk02-cr – no waiting
Jun 27 14:30:06 [2053] pcmk01 crmd: info: te_rsc_command: Action 5 confirmed – no wait
Jun 27 14:30:06 [2053] pcmk01 crmd: notice: run_graph: Transition 5 (Complete=5, Pending=0, Fired=0, Skipped=1, Incomplete=2, Source=/var/lib/pacemaker/pengine/pe-input-5.bz2): Stopped
Jun 27 14:30:06 [2053] pcmk01 crmd: info: do_state_transition: State transition S_TRANSITION_ENGINE -> S_POLICY_ENGINE [ input=I_PE_CALC cause=C_FSA_INTERNAL origin=notify_crmd ]
Jun 27 14:30:06 [2052] pcmk01 pengine: notice: unpack_config: On loss of CCM Quorum: Ignore
Jun 27 14:30:06 [2052] pcmk01 pengine: info: determine_online_status: Node pcmk01-cr is online
Jun 27 14:30:06 [2052] pcmk01 pengine: info: determine_online_status: Node pcmk02-cr is online
Jun 27 14:30:06 [2052] pcmk01 pengine: warning: unpack_rsc_op_failure: Processing failed op monitor for mysql_data01 on pcmk01-cr: not configured (6)
Jun 27 14:30:06 [2052] pcmk01 pengine: error: unpack_rsc_op: Preventing mysql_data01 from re-starting anywhere: operation monitor failed ‘not configured’ (6)
Jun 27 14:30:06 [2052] pcmk01 pengine: warning: unpack_rsc_op_failure: Processing failed op monitor for mysql_data01 on pcmk01-cr: not configured (6)
Jun 27 14:30:06 [2052] pcmk01 pengine: error: unpack_rsc_op: Preventing mysql_data01 from re-starting anywhere: operation monitor failed ‘not configured’ (6)
Jun 27 14:30:06 [2052] pcmk01 pengine: warning: unpack_rsc_op_failure: Processing failed op monitor for mysql_data01 on pcmk02-cr: not configured (6)
Jun 27 14:30:06 [2052] pcmk01 pengine: error: unpack_rsc_op: Preventing mysql_data01 from re-starting anywhere: operation monitor failed ‘not configured’ (6)
Jun 27 14:30:06 [2052] pcmk01 pengine: warning: unpack_rsc_op_failure: Processing failed op monitor for mysql_data01 on pcmk02-cr: not configured (6)
Jun 27 14:30:06 [2052] pcmk01 pengine: error: unpack_rsc_op: Preventing mysql_data01 from re-starting anywhere: operation monitor failed ‘not configured’ (6)
Can you post the output of the following please:
[root@pcmk01 ~]# ip -4 ad 1: lo: mtu 65536 qdisc noqueue state UNKNOWN inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever 2: eth0: mtu 1500 qdisc pfifo_fast state UP qlen 1000 inet 10.0.2.15/24 brd 10.0.2.255 scope global dynamic eth0 valid_lft 83640sec preferred_lft 83640sec 3: eth1: mtu 1500 qdisc pfifo_fast state UP qlen 1000 inet 10.8.8.61/24 brd 10.8.8.255 scope global eth1 valid_lft forever preferred_lft forever 4: eth2: mtu 1500 qdisc pfifo_fast state UP qlen 1000 inet 172.16.21.11/24 brd 172.16.21.255 scope global eth2 valid_lft forever preferred_lft forever 5: eth3: mtu 1500 qdisc pfifo_fast state UP qlen 1000 inet 172.16.22.11/24 brd 172.16.22.255 scope global eth3 valid_lft forever preferred_lft forever# cat /etc/drbd.d/mysql01.res resource mysql01 { protocol C; meta-disk internal; device /dev/drbd0; disk /dev/VolGroup00/lv_drbd; handlers { split-brain "/usr/lib/drbd/notify-split-brain.sh root"; } net { allow-two-primaries no; after-sb-0pri discard-zero-changes; after-sb-1pri discard-secondary; after-sb-2pri disconnect; rr-conflict disconnect; } disk { on-io-error detach; } syncer { verify-alg sha1; } on pcmk01 { address 172.16.22.11:7789; } on pcmk02 { address 172.16.22.12:7790; //because with vagrant I cannot use 7789 for both servers I forward 7790 to 7789 } }# cat /var/lib/pcsd/tokens { "format_version": 2, "data_version": 2, "tokens": { "pcmk01-cr": "828cbd4d-42a6-4ddc-aed1-2604735248ba", "pcmk02-cr": "e7fb15eb-82a3-47dd-bd53-3e1c71af9569" }# pcs resource show --full Master: MySQLClone01 Meta Attrs: master-max=1 master-node-max=1 clone-max=2 clone-node-max=1 notify=true Resource: mysql_data01 (class=ocf provider=linbit type=drbd) Attributes: drbd_resource=mysql01 Operations: start interval=0s timeout=240 (mysql_data01-start-interval-0s) promote interval=0s timeout=90 (mysql_data01-promote-interval-0s) demote interval=0s timeout=90 (mysql_data01-demote-interval-0s) stop interval=0s timeout=100 (mysql_data01-stop-interval-0s) monitor interval=30s (mysql_data01-monitor-interval-30s)# pcs status Cluster name: mysql_cluster Last updated: Mon Jun 27 19:04:40 2016 Last change: Mon Jun 27 18:58:37 2016 by root via cibadmin on pcmk01-cr Stack: corosync Current DC: pcmk02-cr (version 1.1.13-10.el7_2.2-44eb2dd) - partition with quorum 2 nodes and 2 resources configured Online: [ pcmk01-cr pcmk02-cr ] Full list of resources: Master/Slave Set: MySQLClone01 [mysql_data01] mysql_data01 (ocf::linbit:drbd): FAILED pcmk02-cr (unmanaged) mysql_data01 (ocf::linbit:drbd): FAILED pcmk01-cr (unmanaged) Failed Actions: * mysql_data01_stop_0 on pcmk02-cr 'not configured' (6): call=6, status=complete, exitreason='none', last-rc-change='Mon Jun 27 18:57:20 2016', queued=0ms, exec=57ms * mysql_data01_stop_0 on pcmk01-cr 'not configured' (6): call=6, status=complete, exitreason='none', last-rc-change='Mon Jun 27 18:57:20 2016', queued=0ms, exec=35ms PCSD Status: pcmk01-cr: Online pcmk02-cr: Online Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabledIs there any reason you posted this 4 times?
My sincerest apologies, I was trying since yesterday but never it sent. I though that my responses were discarded. How could I delete the messages? Once again apologies
Ah, I see, not to worry. Due to huge amount of spam all comments are held for moderation. They only appear once manually approved. I’ll get rid of the duplicates.
I’m afraid I’m unable to replicate this, it works fine for me. Do you have firewall and SELinux configured?
I’ve got the following packages:
Can you confirm they match with your system? Also, not sure it’s going to help much, but can you run the following:
I doesn’t use firewalld. I use iptables:
The selinux status:
The packages:
That all looks good. You have some duplicate rules on iptables, but it’s not important. Try setting SELinux to permissive and stopping iptables, then do a resource cleanup and let me know if it makes a difference. I cannot spot any misconfiguration really.
I have tried stopping iptables and setting selinux permissive both CLI and conf file and doesn’t work. I cannot see some conclusive errors to indicate where is the issue. Besides, when I turn off the VMs I cannot turn up the VMs and I have to deploy it from the beginning. Only I get this output when it tries turn up:
Finally, I doesn’t configure the network interfaces enp because I create it as eth with vagrant.
It looks like an issue within your environment. If I were you, I would try to narrow the problem down. Remove Vagrant from the equation. Get two servers up and running, stick with predictable network interface device names, don’t change them and keep everything simple until you get Pacemaker working with DRBD.
Hi Tomas, I come back again. I have mounted the active/passive infraestructura in two physical servers discarding Vagrant. But I am getting the same error, drbd is connected in both servers but when I started to create the resources without cib, drbd resource called mysql_data01 continue unmanaged. In failed actioncs I see the same error
”
* mysql_data01_stop_0 on pcmk01-cr 'not configured' (6): call=6, status=complete, exitreason='none', last-rc-change='Tue Jul 12 15:23:43 2016', queued=0ms, exec=27ms * mysql_data01_stop_0 on pcmk02-cr 'not configured' (6): call=6, status=complete, exitreason='none', last-rc-change='Tue Jul 12 15:23:43 2016', queued=0ms, exec=33ms”
Is there a drbd log where I can check that all is succesfully? On the same hand, is there a cluster log where I can check why this resource is unmanaged? At the moment the only that I have seen in path /var/log/cluster/corosync.log:
”
”
It seems corosync problem but when I check the cluster status it is ok in both servers:
”
”
I am sure that I am following all steps but it is very strange.
I wonder that how to configure active-active mode. Please let me know that way.
I set
———————————————————————————
resource mysql01 { protocol C; meta-disk internal; device /dev/drbd0; disk /dev/sdb; handlers { split-brain "/usr/lib/drbd/notify-split-brain.sh root"; } net { allow-two-primaries yes; after-sb-0pri discard-zero-changes; after-sb-1pri discard-secondary; after-sb-2pri disconnect; rr-conflict disconnect; } disk { on-io-error detach; } syncer { verify-alg sha1; } on pcmk01 { address 172.16.22.11:7789; } on pcmk02 { address 172.16.22.12:7790; } }———————————————————–
——————————————————–
but pcs status is
Cluster name: mysql_cluster Last updated: Mon Jul 4 16:28:30 2016 Last change: Mon Jul 4 16:28:26 2016 by root via cibadmin on pcmk01-cr Stack: corosync Current DC: pcmk02-cr (version 1.1.13-10.el7_2.2-44eb2dd) - partition with quorum 2 nodes and 5 resources configured Online: [ pcmk01-cr pcmk02-cr ] Full list of resources: Master/Slave Set: MySQLClone01 [mysql_data01] mysql_data01 (ocf::linbit:drbd): FAILED pcmk02-cr (unmanaged) mysql_data01 (ocf::linbit:drbd): FAILED pcmk01-cr (unmanaged) mysql_fs01 (ocf::heartbeat:Filesystem): Stopped mysql_service01 (ocf::heartbeat:mysql): Stopped mysql_VIP01 (ocf::heartbeat:IPaddr2): Stopped Failed Actions: * mysql_data01_stop_0 on pcmk02-cr 'not configured' (6): call=20, status=complete, exitreason='none', last-rc-change='Mon Jul 4 16:28:27 2016', queued=0ms, exec=32ms * mysql_data01_stop_0 on pcmk01-cr 'not configured' (6): call=20, status=complete, exitreason='none', last-rc-change='Mon Jul 4 16:28:27 2016', queued=0ms, exec=25ms PCSD Status: pcmk01-cr: Online pcmk02-cr: Online Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabledI use GFS2 for active/active Pacemaker clusters, please see here.
Did you ever receive an answer for these?
“mysql_data01 (ocf::linbit:drbd): FAILED pcmk02-cr (unmanaged)
mysql_data01 (ocf::linbit:drbd): FAILED pcmk01-cr (unmanaged)”
Thank you for reply.
But i want to use just mariadb duplication instead of galera cluster.
Is it possible active-active mode in this post?
I just love this article, thanks for the time in putting this together. I would just like to know, if it would be hard to add Apache into this active / passive setup? I’m trying to make a active / passive LAMP server that’s all
Again thanks for your time.
I tend to keep databases isolated (back-end) and use a separate cluster for Apache (front-end) with front-end proxies on top of it really. Check this post for how to add Apache as a cluster service. Hope this helps.
Thanks for your last reply.
I’ve got two servers running the system from this post without any problems that I know of.
I just have one of two questions if you can help, I have two physical servers would I need to setup this STONITH? If one of my servers goes offline and comes back on, how to I re-sync the SQL and re-add this server back in the cluster as if I do a pc status at commandline, it says no in cluster?
Thanks again
It doesn’t really matter that much what you use, whether it be physical servers, blades, virtual machines etc. The question really is how do you handle split-brain scenarions? You don’t need STONITH if you have some well-tested and proven mechanism that takes care of it.
As for your second question, I don’t know your setup, so cannot advise.
I want to do a Mysql High Availability Cluster But I am not able to do it. When I created Mysql resource
pcs resource create Mysql ocf:heartbeat:mysql params binary=”/usr/bin/mysql” datadir=”/var/lib/mysql” config=”/etc/my.cnf” log=”/var/log/mysqld.log” pid=”/var/run/mysqld/mysqld.pid” socket=”/var/lib/mysql/mysql.sock” op start interval=0s timeout=20s op stop interval=0s timeout=20s op monitor interval=20s
pcs status show that resource Mysql:started [node1 node2] but after some time (5 seconds) It is stopped and also Mysql service or status also stopped on both the nodes
Thank you
What do the logs say?
Log:
2016-07-05T06:49:21.166141Z 0 [Warning] TIMESTAMP with implicit DEFAULT value is deprecated. Please use –explicit_defaults_for_timestamp server option (see documentation for more details).
2016-07-05T06:49:22.384391Z 0 [Warning] InnoDB: New log files created, LSN=45790
2016-07-05T06:49:22.540803Z 0 [Warning] InnoDB: Creating foreign key constraint system tables.
2016-07-05T06:49:22.599347Z 0 [Warning] No existing UUID has been found, so we assume that this is the first time that this server has been started. Generating a new UUID: 9b0bb85c-427c-11e6-b344-0800274eaf5b.
2016-07-05T06:49:22.609981Z 0 [Warning] Gtid table is not ready to be used. Table ‘mysql.gtid_executed’ cannot be opened.
2016-07-05T06:49:22.611483Z 1 [Note] A temporary password is generated for root@localhost: lvwXr+i>_3/!
2016-07-05T06:49:27.861283Z 0 [Warning] TIMESTAMP with implicit DEFAULT value is deprecated. Please use –explicit_defaults_for_timestamp server option (see documentation for more details).
2016-07-05T06:49:27.862086Z 0 [Note] /usr/sbin/mysqld (mysqld 5.7.13) starting as process 2939 …
2016-07-05T06:49:27.869138Z 0 [Note] InnoDB: PUNCH HOLE support available
2016-07-05T06:49:27.869186Z 0 [Note] InnoDB: Mutexes and rw_locks use GCC atomic builtins
2016-07-05T06:49:27.869196Z 0 [Note] InnoDB: Uses event mutexes
This log has no errors.
pcs status
Cluster name: hacluster1
Last updated: Thu Jul 21 05:50:40 2016 Last change: Thu Jul 21 05:50:13 2016 by root via cibadmin on node2
Stack: corosync
Current DC: node1 (version 1.1.13-10.el7_2.2-44eb2dd) – partition with quorum
2 nodes and 2 resources configured
Online: [ node1 node2 ]
Full list of resources:
VIRTUAL_IP_ (ocf::heartbeat:IPaddr2): Started node2
Mysql (ocf::heartbeat:mysql): Stopped
Failed Actions:
* Mysql_start_0 on node1 ‘unknown error’ (1): call=33, status=complete, exitreason=’MySQL server failed to start (pid=10542) (rc=7), please check your installation’,
last-rc-change=’Thu Jul 21 05:50:26 2016′, queued=0ms, exec=550ms
* Mysql_start_0 on node2 ‘unknown error’ (1): call=29, status=complete, exitreason=’MySQL server failed to start (pid=11933) (rc=7), please check your installation’,
last-rc-change=’Thu Jul 21 05:50:27 2016′, queued=0ms, exec=938ms
PCSD Status:
node1: Online
node2: Online
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
Any pacemaker log entries related to ocf::heartbeat:mysql?
why mysql service is stopped ???
Thank you your guide was helping me a lot , i had a lot issues doing this setup with others tuto’s.
Your guide was the good one , all works perfect , with MAC/Parallel.
Question How this setup is good for prod env??
I had setup heartbeat+drbd+mysql on centos 5.5 in the past and still working in prod very good.
but this setup can go to prod env?
This particular setup does not have fencing (neither resource level nor node level), therefore I would not use it in production.
when doing mysql ha cluster I done replication after making mysql resource it works well when there is failover but checking mysql status (service mysqld status) it shows inactive(dead) on both nodes why……???????
Check logs.
please tell
How to create a Mysql resource using pacemaker and corosync on centos7 i am succesfully created two nodes and a resource for virtual ip it works well now i want to create a Mysql resource but not able to create as i mention it stops the mysql service but on the node Mysql resource started i am able to login in mysql on that node but the service is stopped…..?????
Thanks
The article explains how to create what you asked for. If you run into problems, check logs to see what’s failing, and troubleshoot accordingly.
Hey Tomas,
Successfully created Postgresql cluster following your guidelines, awesome write-up, thank you very much!
Welcome :)
Hello,
Does anyone know what is causing this failure below?
“Master/Slave Set: MySQLClone01 [mysql_data01]
mysql_data01 (ocf::linbit:drbd): FAILED pcmk02-cr (unmanaged)
mysql_data01 (ocf::linbit:drbd): FAILED pcmk01-cr (unmanaged)”
Hi.
Do you have any idea how to resolve this?
[root@mysql1 ~]# yum install -y kmod-drbd84 drbd84-utils
Loaded plugins: fastestmirror
Loading mirror speeds from cached hostfile
* base: centos.serverspace.co.uk
* elrepo: mirrors.coreix.net
* extras: mirrors.coreix.net
* updates: mirror.sov.uk.goscomb.net
Package drbd84-utils-8.9.6-1.el7.elrepo.x86_64 already installed and latest version
Resolving Dependencies
–> Running transaction check
—> Package kmod-drbd84.x86_64 0:8.4.8-1_2.el7.elrepo will be installed
–> Processing Dependency: kernel(crypto_shash_setkey) = 0xad34f5e2 for package: kmod-drbd84-8.4.8-1_2.el7.elrepo.x86_64
–> Processing Dependency: kernel(crypto_shash_digest) = 0xa2f07728 for package: kmod-drbd84-8.4.8-1_2.el7.elrepo.x86_64
–> Processing Dependency: kernel(crypto_destroy_tfm) = 0x8f944a92 for package: kmod-drbd84-8.4.8-1_2.el7.elrepo.x86_64
–> Processing Dependency: kernel(crypto_alloc_shash) = 0x848fdfcb for package: kmod-drbd84-8.4.8-1_2.el7.elrepo.x86_64
–> Processing Dependency: kernel(crypto_alloc_ahash) = 0x035deac4 for package: kmod-drbd84-8.4.8-1_2.el7.elrepo.x86_64
–> Processing Dependency: kernel(crypto_ahash_finup) = 0xc30b20a1 for package: kmod-drbd84-8.4.8-1_2.el7.elrepo.x86_64
–> Processing Dependency: kernel(crypto_ahash_final) = 0xb2c3ef50 for package: kmod-drbd84-8.4.8-1_2.el7.elrepo.x86_64
–> Processing Dependency: kernel >= 3.10.0-514.el7 for package: kmod-drbd84-8.4.8-1_2.el7.elrepo.x86_64
–> Finished Dependency Resolution
Error: Package: kmod-drbd84-8.4.8-1_2.el7.elrepo.x86_64 (elrepo)
Requires: kernel(crypto_ahash_finup) = 0xc30b20a1
Installed: kernel-3.10.0-327.el7.x86_64 (@anaconda)
kernel(crypto_ahash_finup) = 0xecb40033
Installed: kernel-3.10.0-327.36.3.el7.x86_64 (@updates)
kernel(crypto_ahash_finup) = 0xecb40033
Installed: kernel-debug-3.10.0-327.36.3.el7.x86_64 (@updates)
kernel(crypto_ahash_finup) = 0x7e16c908
Error: Package: kmod-drbd84-8.4.8-1_2.el7.elrepo.x86_64 (elrepo)
Requires: kernel(crypto_shash_setkey) = 0xad34f5e2
Installed: kernel-3.10.0-327.el7.x86_64 (@anaconda)
kernel(crypto_shash_setkey) = 0xeedcd625
Installed: kernel-3.10.0-327.36.3.el7.x86_64 (@updates)
kernel(crypto_shash_setkey) = 0xeedcd625
Installed: kernel-debug-3.10.0-327.36.3.el7.x86_64 (@updates)
kernel(crypto_shash_setkey) = 0x3a236648
Error: Package: kmod-drbd84-8.4.8-1_2.el7.elrepo.x86_64 (elrepo)
Requires: kernel(crypto_shash_digest) = 0xa2f07728
Installed: kernel-3.10.0-327.el7.x86_64 (@anaconda)
kernel(crypto_shash_digest) = 0x8033678b
Installed: kernel-3.10.0-327.36.3.el7.x86_64 (@updates)
kernel(crypto_shash_digest) = 0x8033678b
Installed: kernel-debug-3.10.0-327.36.3.el7.x86_64 (@updates)
kernel(crypto_shash_digest) = 0xf53f7270
Error: Package: kmod-drbd84-8.4.8-1_2.el7.elrepo.x86_64 (elrepo)
Requires: kernel(crypto_ahash_final) = 0xb2c3ef50
Installed: kernel-3.10.0-327.el7.x86_64 (@anaconda)
kernel(crypto_ahash_final) = 0x1995b8e7
Installed: kernel-3.10.0-327.36.3.el7.x86_64 (@updates)
kernel(crypto_ahash_final) = 0x1995b8e7
Installed: kernel-debug-3.10.0-327.36.3.el7.x86_64 (@updates)
kernel(crypto_ahash_final) = 0x14cffb96
Error: Package: kmod-drbd84-8.4.8-1_2.el7.elrepo.x86_64 (elrepo)
Requires: kernel(crypto_destroy_tfm) = 0x8f944a92
Installed: kernel-3.10.0-327.el7.x86_64 (@anaconda)
kernel(crypto_destroy_tfm) = 0x5dbe8093
Installed: kernel-3.10.0-327.36.3.el7.x86_64 (@updates)
kernel(crypto_destroy_tfm) = 0x5dbe8093
Installed: kernel-debug-3.10.0-327.36.3.el7.x86_64 (@updates)
kernel(crypto_destroy_tfm) = 0x94d1a071
Error: Package: kmod-drbd84-8.4.8-1_2.el7.elrepo.x86_64 (elrepo)
Requires: kernel(crypto_alloc_shash) = 0x848fdfcb
Installed: kernel-3.10.0-327.el7.x86_64 (@anaconda)
kernel(crypto_alloc_shash) = 0x5be5c8ee
Installed: kernel-3.10.0-327.36.3.el7.x86_64 (@updates)
kernel(crypto_alloc_shash) = 0x5be5c8ee
Installed: kernel-debug-3.10.0-327.36.3.el7.x86_64 (@updates)
kernel(crypto_alloc_shash) = 0x7946d063
Error: Package: kmod-drbd84-8.4.8-1_2.el7.elrepo.x86_64 (elrepo)
Requires: kernel >= 3.10.0-514.el7
Installed: kernel-3.10.0-327.el7.x86_64 (@anaconda)
kernel = 3.10.0-327.el7
Installed: kernel-3.10.0-327.36.3.el7.x86_64 (@updates)
kernel = 3.10.0-327.36.3.el7
Installed: kernel-debug-3.10.0-327.36.3.el7.x86_64 (@updates)
kernel = 3.10.0-327.36.3.el7
Error: Package: kmod-drbd84-8.4.8-1_2.el7.elrepo.x86_64 (elrepo)
Requires: kernel(crypto_alloc_ahash) = 0x035deac4
Installed: kernel-3.10.0-327.el7.x86_64 (@anaconda)
kernel(crypto_alloc_ahash) = 0x28226cfc
Installed: kernel-3.10.0-327.36.3.el7.x86_64 (@updates)
kernel(crypto_alloc_ahash) = 0x28226cfc
Installed: kernel-debug-3.10.0-327.36.3.el7.x86_64 (@updates)
kernel(crypto_alloc_ahash) = 0x0cd07bd3
You could try using –skip-broken to work around the problem
You could try running: rpm -Va –nofiles –nodigest
[root@mysql1 ~]#
It would seem the packages are not compatible with the kernel.
I use kernel 3.10.0-327.36.3.el7 with kmod-drbd84-8.4.7. I haven’t upgraded to kmod-drbd84-8.4.8 yet.
According to changelog, kmod-drbd84-8.4.8-1_2.el7 requires kernel 3.10.0-514.el7. Therefore upgrade your RHEL kernel to the version specified, wait for CentOS 7.3 to be released, or downgrade to kmod-drbd84-8.4.7.
Hi.
That worked. Maybe a slight change to your guide but:
yum install -y kmod-drbd84-8.4.7 drbd84-utils
It works without all these errors. I guess its due to a newer version in yum.
See my previous reply, it explains your problem.
As Tomas has said it’s the kernel version. I’ve just checked and CentOS 7.3 (1611) has kernel 3.10.0-514.el7 in it. You can get it now if you enable the continuous release repository (# yum-config-manager –enable cr), just be aware that the CR repo doesn’t have the same QA testing on the packages as the official release, which I would expect to be released relatively soon. Good to test with in a pre-production environment, not so much in production.
Thank you for this, I was at a stand still..
Welcome.
Hi,
Our mounting point is /data than what is path for datadir , pid & scoket location on pcs cluster resoure
Pls. confirm
Thanks & Regards,
Manohar
Change the datadir to point to your mountpoint, the rest should remain the same.
I accidentally delete the “tokens” file from the path /var/lib/pcsd/
now I’m failed when I trying to run “pcs cluster auth …”
Please advise when this file create and how can I recreate it?
The tokens file is written when you run pcs cluster auth. If I were you, I’d likely destroy the cluster configuration and start over.
Actually that what I did, run pcs cluster destroy on both nodes and want to start from scratch. run:
1. passwd hacluster
2. systemctl start pcsd.service
systemctl enable pcsd.service
3. pcs cluster auth pcmk01-cr pcmk02-cr -u hacluster -p passwd
right after this command I’m getting:
pcs cluster auth pcmk01-cr pcmk02-cr -u hacluster -p passwd –debug
Running: /usr/bin/ruby -I/usr/lib/pcsd/ /usr/lib/pcsd/pcsd-cli.rb auth
–Debug Input Start–
{“username”: “hacluster”, “local”: false, “nodes”: [“pcmk01-cr”, “pcmk02-cr”], “password”: “passwd”, “force”: false}
–Debug Input End–
Return Value: 0
–Debug Output Start–
{
“status”: “ok”,
“data”: {
“auth_responses”: {
“pcmk02-cr”: {
“status”: “noresponse”
},
“pcmk01-cr”: {
“status”: “noresponse”
}
},
“sync_successful”: true,
“sync_nodes_err”: [
],
“sync_responses”: {
}
},
“log”: [
“I, [2017-02-07T15:39:02.931805 #9565] INFO — : PCSD Debugging enabled\n”,
“D, [2017-02-07T15:39:02.932029 #9565] DEBUG — : Did not detect RHEL 6\n”,
“I, [2017-02-07T15:39:02.932120 #9565] INFO — : Running: /usr/sbin/corosync-cmapctl totem.cluster_name\n”,
“I, [2017-02-07T15:39:02.932201 #9565] INFO — : CIB USER: hacluster, groups: \n”,
“D, [2017-02-07T15:39:02.954535 #9565] DEBUG — : [\”totem.cluster_name (str) = RV_cluster\\n\”]\n”,
“D, [2017-02-07T15:39:02.954797 #9565] DEBUG — : Duration: 0.022273072s\n”,
“I, [2017-02-07T15:39:02.954952 #9565] INFO — : Return Value: 0\n”,
“W, [2017-02-07T15:39:02.955916 #9565] WARN — : Cannot read config ‘tokens’ from ‘/var/lib/pcsd/tokens’: No such file or directory – /var/lib/pcsd/tokens\n”,
“E, [2017-02-07T15:39:02.956091 #9565] ERROR — : Unable to parse tokens file: A JSON text must at least contain two octets!\n”,
“I, [2017-02-07T15:39:02.956166 #9565] INFO — : SRWT Node: pcmk02-cr Request: check_auth\n”,
“E, [2017-02-07T15:39:02.956216 #9565] ERROR — : Unable to connect to node pcmk02-cr, no token available\n”,
“W, [2017-02-07T15:39:02.955639 #9565] WARN — : Cannot read config ‘tokens’ from ‘/var/lib/pcsd/tokens’: No such file or directory – /var/lib/pcsd/tokens\n”,
“E, [2017-02-07T15:39:02.956402 #9565] ERROR — : Unable to parse tokens file: A JSON text must at least contain two octets!\n”,
“I, [2017-02-07T15:39:02.956461 #9565] INFO — : SRWT Node: pcmk01-cr Request: check_auth\n”,
“E, [2017-02-07T15:39:02.956540 #9565] ERROR — : Unable to connect to node pcmk01-cr, no token available\n”,
“I, [2017-02-07T15:39:02.979164 #9565] INFO — : No response from: pcmk02-cr request: /auth, exception: getaddrinfo: Temporary failure in name resolution\n”,
“I, [2017-02-07T15:39:02.979392 #9565] INFO — : No response from: pcmk01-cr request: /auth, exception: getaddrinfo: Temporary failure in name resolution\n”
]
}
–Debug Output End–
Error: Unable to communicate with pcmk01-cr
Error: Unable to communicate with pcmk02-cr
You may have hit a bug, see here: https://bugs.launchpad.net/ubuntu/+source/pcs/+bug/1584365
Also, it says “Temporary failure in name resolution”. Can you resolve pcmk01-cr and pcmk02-cr?
When you say resolve what do you mean?
do you have any command to give me for checking this resolving?
I meant DNS resolution. What do the below commands return?
You need to have the bind-utils package installed for the above to work.
[root@rvpcmk01 ~]host rvpcmk01-cr
;; connection timed out; no servers could be reached
[root@rvpcmk01 ~]# host rvpcmk02-cr
;; connection timed out; no servers could be reached
[root@rvpcmk01 ~]# yum list installed | grep bind-utils
bind-utils.x86_64 32:9.9.4-29.el7_2.3 @ora-local-patches
[root@rvpcmk01 ~]#
I see that you cannot resolve those names. Do you have hosts file entries? The error that you posted previously
I suspect it’s a name resolution issue.
Yes I have.
CentOS7-Minimal-rvpcmk02
[root@rvpcmk02 pcsd]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
#::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
172.17.235.109 rvpcmkvip
172.17.235.43 rvpcmk01
172.17.235.44 rvpcmk02
172.17.235.75 rvpcmk01-cr
172.17.235.106 rvpcmk02-cr
172.17.235.119 rvpcmk01-drbd
172.17.235.46 rvpcmk02-drbd
CentOS7-Minimal-rvpcmk01
[root@rvpcmk01 pcsd]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
#::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
172.17.235.109 rvpcmkvip
172.17.235.43 rvpcmk01
172.17.235.44 rvpcmk02
172.17.235.75 rvpcmk01-cr
172.17.235.106 rvpcmk02-cr
172.17.235.119 rvpcmk01-drbd
172.17.235.46 rvpcmk02-drbd
Do you have Corosync, DRBD and VIP on the same vlan?
How’s network configured for 172.17.235.75 and 172.17.235.106? Can you post the output of network-scripts?
Yes.
I already have other setup on centos7 +GNOME that everything their works fine.
Now I’m trying to configure exactly the same setup on centos7 minimal.
Is the configuration the same then?
Post the output of the following, and I’ll try to replicate during the weekend when having a moment:
Also post the versions of DRBD and MariaDB if you have these installed. And network-scripts configuration for the Corosync ring.
I still don’t have DRBD installed…
Here all what you asked…
I really appreciate you help!
thanks thanks!!!
[root@rvpcmk01 ~]# uname -r
3.10.0-327.el7.x86_64
(it’s the same for both machines).
[root@rvpcmk01 HARADview]# rpm -q pacemaker corosync pcs resource-agents
pacemaker-1.1.15-11.el7_3.2.x86_64
corosync-2.4.0-4.el7.x86_64
pcs-0.9.143-15.el7.x86_64
resource-agents-3.9.5-82.el7_3.4.x86_64
[root@rvpcmk01 HARADview]# cat /etc/sysconfig/network-scripts/ifcfg-ens256
#Corosync ring0
HWADDR=00:0C:29:DE:F6:D2
TYPE=Ethernet
BOOTPROTO=none
IPADDR=172.17.235.75
PREFIX=24
GATEWAY=172.17.235.1
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_PEERDNS=yes
IPV6_PEERROUTES=yes
IPV6_FAILURE_FATAL=no
NAME=ens256
UUID=3e1cc096-f07c-484c-9507-1fd4511cae25
ONBOOT=yes
[root@rvpcmk02 ~]# cat /etc/sysconfig/network-scripts/ifcfg-ens256
#Corosync ring0
HWADDR=00:0C:29:C0:6A:9B
TYPE=Ethernet
BOOTPROTO=none
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
NAME=ens256
UUID=6df2eb7e-c6a4-455f-a760-334e735bca07
ONBOOT=yes
IPADDR=172.17.235.106
PREFIX=24
GATEWAY=172.17.235.1
IPV6_PEERDNS=yes
IPV6_PEERROUTES=yes
* p.s
Look I saw in some article in the network suggestion to check telnet between machine using port 2224.
When I perform it from node1 to node2 I got Connected:
[root@rvpcmk01 HARADview]# telnet rvpcmk02-cr 2224
Trying 172.17.235.106…
Connected to rvpcmk02-cr.
Escape character is ‘^]’.
When perform it from node2 to node1 I got Connection refused:
[root@rvpcmk02 ~]# telnet rvpcmk01-cr 2224
Trying 172.17.235.75…
telnet: connect to address 172.17.235.75: Connection refused
and when I perform it from node1 to node1 I got Connection refused:
[root@rvpcmk01 HARADview]# telnet rvpcmk01-cr 2224
Trying 172.17.235.75…
telnet: connect to address 172.17.235.75: Connection refused
You obviously need to fix the network issue. Is there anything listening on a TCP port 2224 on the node1? Check with netstat or ss. How about firewall?
Why do you have a gateway defined for the Corosync network interface?
I think you placed your LAN, Corosync and DRBD on the same subnet, didn’t you? If each of them has a gateway defined, then you need to configure ARP filtering, implement source-based routing, and even then I’m not sure if it’s going to work.
Hi Again,
I check your the is someone listenin on a TCP port 2224 on node 1 and it’s seems nothing is listening (I put the out put of ss -ta below), is it o.k??
Firewall & IPtables services are disabled.
[root@rvpcmk01 HARADview]# ss -at
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 128 *:60970 *:*
LISTEN 0 128 *:sunrpc *:*
LISTEN 0 32 *:ftp *:*
LISTEN 0 128 *:ssh *:*
LISTEN 0 100 127.0.0.1:smtp *:*
ESTAB 0 36 172.17.235.43:ssh 172.17.230.57:56547
ESTAB 0 0 172.17.235.43:ssh 172.17.230.57:56548
LISTEN 0 128 :::sunrpc :::*
LISTEN 0 128 :::ssh :::*
LISTEN 0 100 ::1:smtp :::*
LISTEN 0 128 :::35652 :::*
Nope, it’s not OK, if the service is not listening. I suspect your network configuration is wrong, please check the blog post for how I’ve configured it.
When I ran: ‘systemctl start pcsd’ on “rvpcmk01” and recheck for listening port 2224:
[root@rvpcmk01 HARADview]# ss -at ‘( dport = :2224 or sport = :2224 )’
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 128 :::efi-mg :::*
It’s seems that now server is listening to port 2224 but still when trying to to do telnet from node 2 ( (‘rvpcmk02’) to rvpcmk01-cr I got connection refused.
[root@rvpcmk02 ~]# telnet rvpcmk01-cr 2224
Trying 172.17.235.75…
telnet: connect to address 172.17.235.75: Connection refused
actually I don’t understand how the port 2224 that opened now on ‘rvpcmk01’ should be also opened for corosync ‘rvpcmk01-cr’ which have different IP.
Please advise.
You messed up your network configuration, please see my previous replies. You get a connection refused error because the service listens on a different IP than it should be. I suggest you either stick to one single IP on your LAN and bind everything to it, or use different subnets as per my blog post.
How did it happened that the service listen to different IP than it should??
Can I use instead the same IPs for Corosync and LAN?
Can it cause a problems if LAN NIC & Corosync NIC will be on the same subnet?
I don’t know how did that happen, but heartbeat interfaces should be placed on a non-routable vlan.
So I deleted my servers and started from scratch.
everything was configured properly until the point I had to start the cluster.
I’m getting a message: “Unable to connect to rvpcmk01-cr ([Errno 111] Connection refused)” for node 1 while other node started successfully.
below I attached the error.
iptables & firewalld are disabled so what can be the reason for this connection refused?
[root@rvpcmk01 /]# pcs cluster setup –name RADview_Cluster rvpcmk01-cr rvpcmk02-cr
Shutting down pacemaker/corosync services…
Redirecting to /bin/systemctl stop pacemaker.service
Redirecting to /bin/systemctl stop corosync.service
Killing any remaining services…
Removing all cluster configuration files…
rvpcmk01-cr: Succeeded
rvpcmk02-cr: Succeeded
Synchronizing pcsd certificates on nodes rvpcmk01-cr, rvpcmk02-cr…
rvpcmk01-cr: Success
rvpcmk02-cr: Success
Restaring pcsd on the nodes in order to reload the certificates…
rvpcmk01-cr: Success
rvpcmk02-cr: Success
[root@rvpcmk01 /]# pcs status
Error: cluster is not currently running on this node
[root@rvpcmk01 /]# pcs cluster start –all
rvpcmk01-cr: Unable to connect to rvpcmk01-cr ([Errno 111] Connection refused)
rvpcmk02-cr: Starting Cluster…
Error: unable to start all nodes
rvpcmk01-cr: Unable to connect to rvpcmk01-cr ([Errno 111] Connection refused)
Connection might be refused due to incorrect authentication.
Eventually I stop & start the cluster once again and nodes started but still so issues like I replay in 08/02/2017 at 3:58 pm.
can you please take a look on the last replay from me??
(By the wat how can we solve this case issues with incorrect authentication?
So does it work now?
O.k so I take snapshot back to the state before start configure the PCS and start again the configuration, I saw my problem start with the authentication process.
I ran from node1: pcs cluster auth rvpcmk01-cr rvpcmk02-cr -u hacluster -p passwd –debug
and saw errors, I also check the tokens files on both nodes and it’s seems that token for node1 on node2 didn’t created.
WHAT CAN BE THE REASON FOR THAT? it’s seems that I have problem of connection between nodes.
I added the hostname & the IP of both corosync nic to /etc/hosts file on both servers.
What else I missed?
Here are the logs from the “auth” command and the output of tokens on both nodes.
[root@rvpcmk01 pcsd]# pcs cluster auth rvpcmk01-cr rvpcmk02-cr -u hacluster -p passwd –debug
Running: /usr/bin/ruby -I/usr/lib/pcsd/ /usr/lib/pcsd/pcsd-cli.rb auth
–Debug Input Start–
{“username”: “hacluster”, “local”: false, “nodes”: [“rvpcmk01-cr”, “rvpcmk02-cr”], “password”: “passwd”, “force”: false}
–Debug Input End–
Return Value: 0
–Debug Output Start–
{
“status”: “ok”,
“data”: {
“auth_responses”: {
“rvpcmk02-cr”: {
“status”: “ok”,
“token”: “be57712c-aa2c-4255-b2b7-8d9161e3302c”
},
“rvpcmk01-cr”: {
“status”: “ok”,
“token”: “bbbb202e-004b-4102-b0f4-5f98491e27f1”
}
},
“sync_successful”: true,
“sync_nodes_err”: [
],
“sync_responses”: {
}
},
“log”: [
“I, [2017-02-08T16:05:52.029970 #30725] INFO — : PCSD Debugging enabled\n”,
“D, [2017-02-08T16:05:52.030161 #30725] DEBUG — : Did not detect RHEL 6\n”,
“I, [2017-02-08T16:05:52.030251 #30725] INFO — : Running: /usr/sbin/corosync-cmapctl totem.cluster_name\n”,
“I, [2017-02-08T16:05:52.030337 #30725] INFO — : CIB USER: hacluster, groups: \n”,
“D, [2017-02-08T16:05:52.036998 #30725] DEBUG — : []\n”,
“D, [2017-02-08T16:05:52.037136 #30725] DEBUG — : Duration: 0.006637403s\n”,
“I, [2017-02-08T16:05:52.037276 #30725] INFO — : Return Value: 1\n”,
“W, [2017-02-08T16:05:52.037460 #30725] WARN — : Cannot read config ‘corosync.conf’ from ‘/etc/corosync/corosync.conf’: No such file or directory – /etc/corosync/corosync.conf\n”,
“W, [2017-02-08T16:05:52.038405 #30725] WARN — : Cannot read config ‘tokens’ from ‘/var/lib/pcsd/tokens’: No such file or directory – /var/lib/pcsd/tokens\n”,
“E, [2017-02-08T16:05:52.038586 #30725] ERROR — : Unable to parse tokens file: A JSON text must at least contain two octets!\n”,
“I, [2017-02-08T16:05:52.038657 #30725] INFO — : SRWT Node: rvpcmk02-cr Request: check_auth\n”,
“E, [2017-02-08T16:05:52.038740 #30725] ERROR — : Unable to connect to node rvpcmk02-cr, no token available\n”,
“W, [2017-02-08T16:05:52.038971 #30725] WARN — : Cannot read config ‘tokens’ from ‘/var/lib/pcsd/tokens’: No such file or directory – /var/lib/pcsd/tokens\n”,
“E, [2017-02-08T16:05:52.039077 #30725] ERROR — : Unable to parse tokens file: A JSON text must at least contain two octets!\n”,
“I, [2017-02-08T16:05:52.039137 #30725] INFO — : SRWT Node: rvpcmk01-cr Request: check_auth\n”,
“E, [2017-02-08T16:05:52.039182 #30725] ERROR — : Unable to connect to node rvpcmk01-cr, no token available\n”,
“I, [2017-02-08T16:05:52.202095 #30725] INFO — : Running: /usr/sbin/pcs status nodes corosync\n”,
“I, [2017-02-08T16:05:52.202234 #30725] INFO — : CIB USER: hacluster, groups: \n”,
“D, [2017-02-08T16:05:52.333082 #30725] DEBUG — : []\n”,
“D, [2017-02-08T16:05:52.333295 #30725] DEBUG — : Duration: 0.130803488s\n”,
“I, [2017-02-08T16:05:52.333421 #30725] INFO — : Return Value: 1\n”,
“W, [2017-02-08T16:05:52.333557 #30725] WARN — : Cannot read config ‘tokens’ from ‘/var/lib/pcsd/tokens’: No such file or directory – /var/lib/pcsd/tokens\n”,
“E, [2017-02-08T16:05:52.333670 #30725] ERROR — : Unable to parse tokens file: A JSON text must at least contain two octets!\n”,
“I, [2017-02-08T16:05:52.334593 #30725] INFO — : Saved config ‘tokens’ version 1 3beaea374be91220ce9b4a04728b6cc5d1d09835 to ‘/var/lib/pcsd/tokens’\n”
]
}
–Debug Output End–
rvpcmk01-cr: Authorized
rvpcmk02-cr: Authorized
[root@rvpcmk01 pcsd]# cat tokens
{
“format_version”: 2,
“data_version”: 2,
“tokens”: {
“rvpcmk01-cr”: “758f670d-434c-4592-80cc-c471602fd7f7”,
“rvpcmk02-cr”: “73b14b5f-9ef7-4047-bacb-f3d3878a24b1”
}
}
[root@rvpcmk02 pcsd]# cat tokens
{
“format_version”: 2,
“data_version”: 1,
“tokens”: {
“rvpcmk02-cr”: “bb88548a-81db-4237-a6b5-fb1ed380ead1”
}
PLEASE ADVISE…
Your tokens don’t match. Try the following, stop pacemaker and corosync:
Remove (or rename)
/etc/corosync/corosync.conf. Without that pcs cluster auth won’t create the tokens file. Provide an empty config for/var/lib/pcsd/pcs_settings.conf(remove any cluster reference as well as set data version to 0). Then authenticate with pcs cluster auth and create a cluster with pcs cluster setup.unfortunately no, I sent replay to you in the last hour with what I think cause all the problems, I cannot see the message now, maybe you need to aprrove it.
I do, yes. Otherwise this page would be filled with spam :)
Regarding what you suggest.
1. I don’t have file /etc/corosync/corosync.conf , I think it’s create only after “pcs cluster setup” and I took snapshot to point before I run it.
2. I also doesn’t have the file /var/lib/pcsd/pcs_settings.conf
After installing PCS and trying to auth I have only these files under /var/lib/pcsd/:
pcsd.cookiesecret pcsd.crt pcsd.key pcs_users.conf tokens
Again when I tried to auth I got errors and saw tokens don’t match and I don’t understand why :(
[root@rvpcmk01 HARADview]# cat /var/lib/pcsd/tokens
{
“format_version”: 2,
“data_version”: 2,
“tokens”: {
“rvpcmk01-cr”: “e10dd4d8-d1b3-4356-bc4e-9d1ff554d457”,
“rvpcmk02-cr”: “9812a0d0-900d-4cc4-9e6d-5f9cffe88d21”
}
[root@rvpcmk02 HARADview]# cat /var/lib/pcsd/tokens
{
“format_version”: 2,
“data_version”: 1,
“tokens”: {
“rvpcmk01-cr”: “ccd42145-dc15-4988-8577-dc7533059f84”,
“rvpcmk02-cr”: “8264d49d-d5b5-46ca-8f91-4bec991c602c”
}
[root@rvpcmk01 /]# pcs cluster sync
rvpcmk01-cr: Succeeded
rvpcmk02-cr: Succeeded
[root@rvpcmk02 HARADview]# pcs cluster sync
Unable to connect to rvpcmk01-cr ([Errno 111] Connection refused)
Error: Unable to set corosync config: Unable to connect to rvpcmk01-cr ([Errno 111] Connection refused)
[root@rvpcmk01 /]# pcs status
Cluster name: RADview_Cluster
Stack: corosync
Current DC: rvpcmk01-cr (version 1.1.15-11.el7_3.2-e174ec8) – partition with quorum
Last updated: Wed Feb 8 17:56:49 2017 Last change: Wed Feb 8 17:51:33 2017 by root via cibadmin on rvpcmk01-cr
2 nodes and 0 resources configured
Online: [ rvpcmk01-cr ]
OFFLINE: [ rvpcmk02-cr ]
No resources
PCSD Status:
rvpcmk01-cr: Online
rvpcmk02-cr: Online
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabled
[root@rvpcmk02 HARADview]# pcs status
Cluster name: RADview_Cluster
WARNING: no stonith devices and stonith-enabled is not false
Stack: corosync
Current DC: rvpcmk02-cr (version 1.1.15-11.el7_3.2-e174ec8) – partition WITHOUT quorum
Last updated: Wed Feb 8 17:52:21 2017 Last change: Wed Feb 8 17:47:06 2017 by hacluster via crmd on rvpcmk02-cr
2 nodes and 0 resources configured
Node rvpcmk01-cr: UNCLEAN (offline)
Online: [ rvpcmk02-cr ]
No resources
PCSD Status:
rvpcmk01-cr: Offline
rvpcmk02-cr: Online
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabled
Hi,
Pls. confirm This configuration is running with centos 7.3
uname -r
3.10.0-514.6.1.el7.x86_64
I have it up and running on CentOS 7.2. I have not tested the configuration on CentOS 7.3.
Hi (again :) )
I create my own resource agent for handle my private services.
I create resource with the RA I created and it’s works fine.
when my resource is failing and I run the command “pcs status” I can see an error message about my failed resource.
Now my question is if I can handle the error message that displayed their ??
for example when a function (monitor) inside my resource agent is failed I’m getting:
Failed Actions:
* MyServicesResource_monitor_120000 on rvpcmk01-cr ‘unknown error’ (1): call=63, status=complete, exitreason=’none’,
last-rc-change=’Tue Feb 28 16:17:46 2017′, queued=0ms, exec=1274ms
for example can I put my customize the “unknown error” string or the “exitreason=’none'” ??
Hi Lidor. I’m sorry, but I don’t know.
How can I make resource to run only on the Master/Active node?
I have oracle resource that I want to be run (and monitor) only on the server that is Active and actually have data.
of cource in case of switchover resource should stop running on the active node and start running on the NEW active (master) node.
In a failover cluster scenario, a resource runs on the active node only. It does not run on the passive node, so you monitor the node that is active.
What about the situation before switchover? when both nodes are running o.k , one is active and the second is passive.
I’m getting error message from the resource that start operation failed on the passive node – that what I want to prevent.
resource operations (monitor/stop/start) should be execute only on the active node.
Yes, when everything is OK, then one node is an active node, and one is a passive node. You only monitor the one that’s active, actually you monitor the VIP as it floats depending on which server the service is running on. If your passive node tries to become an active node while the actual active node is still “active”, then I suspect you have a split-brain situation and need to fence the node.
In you procedure you tell us “To avoid issues with SELinux, for the time being, we are going to exempt DRBD processes from SELinux control” using the command:
[ALL]# semanage permissive -a drbd_t
now my question is:
what is drbd_t? is default DRBD process name? where & when it’s defined?
Please see here for the answers to your questions:
what is it “man 8 drbd_selinux”? a command? where I should run it?
[root@rvpcmk02 ~]# man 8 drbd_selinux
No manual entry for drbd_selinux in section 8
It’s a man page, section 8, for drbd_selinux.
You may not have SELinux man pages installed by default. If that’s the case, do the following:
At this point you should have all SELinux man pages installed on your system.
How to get VIP IP adrress in vmware workstation or in virtualbox.
The VIP address is the one you assign yourself regardless of a virtualisation platform the cluster runs on.
Hi,
I have the following error:
]# mysql_install_db –datadir=/mnt –user=mysql
chown: cambiando el propietario de «/mnt»: Sistema de ficheros de sólo lectura
Cannot change ownership of the database directories to the ‘mysql’
user. Check that you have the necessary permissions and try again.
I suppose there’s something regarding the user mysql which is not configured or misconfigured (password maybe??) , but i don’t know the file i should change to make it work… can someone give me a hand on this?
Thanks so much in advance,
Does the mysql user have read/write access to
/mnt?Well, I’ve manually given permission, but after executing that command and continuing with the other one:
]# mysql_secure_installation
I get the following error:
password for the root user. If you’ve just installed MariaDB, and
you haven’t set the root password yet, the password will be blank,
so you should just press enter here.
Enter current password for root (enter for none):
ERROR 2002 (HY000): Can’t connect to local MySQL server through socket ‘/var/lib/mysql/mysql.sock’ (2)
But as far as i remember, i haven’t put any password before…
Thanks so much!
Is the MariaDB service running? Make sure it’s started.
Well, i forgot that line, sorry…
Continuing with the configuration, there’s some error on permissions i’m sure i’ve overseen…
Failed Actions:
* mysql_service01_start_0 on db03 ‘insufficient privileges’ (4): call=26, status=complete, exitreason=’Directory /var/lib/mysql is not writable by mysql’,
but checking file permissions:
drwxr-xr-x 4 mysql mysql 147 may 4 09:18 mysql
Thanks so much for the great help
Thought so, no worries. That’s what I’ve learnt over the years – most issues tend to occur when you skip one or another part of the tutorial.
Check SELinux context, also check that files and folders inside
/var/lib/mysqlhave proper ownership.Hi Tomas,
i would like to ask if the ” Configure Pacemaker Cluster ” part will be execute also in the slave node ?
i wish you will reply :)
i’m having a problem that my slave won’t start the service01 and VIP01
When you commit changes Pacemaker will start resources on both cluster nodes.
Almost finished except i can’t start slave node of mysql on node2
[node2]# pcs status
Cluster name: lbcluster
Stack: corosync
Current DC: node3lb.lanbilling.ru (version 1.1.16-12.el7_4.5-94ff4df) – partition with quorum
Last updated: Tue Dec 19 19:09:37 2017
Last change: Tue Dec 19 18:36:04 2017 by root via cibadmin on node2lb.lanbilling.ru
2 nodes configured
6 resources configured
Online: [ node2lb.lanbilling.ru node3lb.lanbilling.ru ]
Full list of resources:
virtual_ip (ocf::heartbeat:IPaddr2): Started node3lb.lanbilling.ru
webserver (ocf::heartbeat:apache): Started node3lb.lanbilling.ru
Master/Slave Set: MySQLClone01 [mysql_data01]
Masters: [ node3lb.lanbilling.ru ]
Slaves: [ node2lb.lanbilling.ru ]
mysql_fs01 (ocf::heartbeat:Filesystem): Started node3lb.lanbilling.ru
mysql_service01 (ocf::heartbeat:mysql): Started node3lb.lanbilling.ru
Failed Actions:
* mysql_service01_start_0 on node2lb.lanbilling.ru ‘unknown error’ (1): call=25, status=complete, exitreason=’MySQL server failed to start (pid=8292) (rc=1), please check your installation’,
last-rc-change=’Tue Dec 19 18:36:05 2017′, queued=0ms, exec=3003ms
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabled
What log file should i look for bellow error
* mysql_service01_start_0 on node2lb.lanbilling.ru ‘unknown error’ (1): call=25, status=complete, exitreason=’MySQL server failed to start (pid=8292) (rc=1), please check your installation’,
You can take a look at
/var/log/cluster/corosync.log.After completing setup I ran pcs status it gives me following error
[root@pcmk01 ~]# pcs status
Cluster name: mysql_cluster
Stack: corosync
Current DC: pcmk02-cr (version 1.1.16-12.el7_4.8-94ff4df) – partition with quorum
Last updated: Thu Mar 15 12:38:14 2018
Last change: Thu Mar 15 10:01:27 2018 by root via cibadmin on pcmk01-cr
2 nodes configured
5 resources configured
Online: [ pcmk01-cr pcmk02-cr ]
Full list of resources:
Master/Slave Set: MySQLClone01 [mysql_data01]
Masters: [ pcmk02-cr ]
Slaves: [ pcmk01-cr ]
mysql_fs01 (ocf::heartbeat:Filesystem): Started pcmk02-cr
mysql_service01 (ocf::heartbeat:mysql): Stopped
mysql_VIP01 (ocf::heartbeat:IPaddr2): Stopped
Failed Actions:
* mysql_service01_start_0 on pcmk01-cr ‘not installed’ (5): call=26, status=complete, exitreason=’Setup problem: couldn’t find command: mysql’,
last-rc-change=’Thu Mar 15 12:36:41 2018′, queued=0ms, exec=99ms
* mysql_service01_start_0 on pcmk02-cr ‘not installed’ (5): call=32, status=complete, exitreason=’Setup problem: couldn’t find command: mysql’,
last-rc-change=’Thu Mar 15 10:03:02 2018′, queued=0ms, exec=108ms
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabled
[root@pcmk01 ~]#
=========================================
This is the command I used to add mysql resource
[pcmk01]# pcs -f clust_cfg resource create mysql_service01 ocf:heartbeat:mysql \
binary=”/usr/local/mysql/bin/mysqld_safe” \
config=”/etc/my.cnf” \
datadir=”/data” \
pid=”/var/lib/mysql/mysql.pid” \
socket=”/var/lib/mysql/mysql.sock” \
additional_parameters=”–bind-address=0.0.0.0″ \
op start timeout=60s \
op stop timeout=60s \
op monitor interval=20s timeout=30s
please help me !
Thanks in advance
The error says “couldn’t find command: mysql” – make sure that you have MySQL installed and that it’s in the PATH. It might help using the which command to return the pathname of the file, e.g.:
Hello Tomas. First of all thanks for all your work on this article !
I’ve follow it and my cluster is setup but I’m unable to automate the down / up of the node.
I’m meaning that I need to manually perform the command `pcs cluster start –all` to get the freshly up node running correctly as a cluster node (none of corosync or drbd service get up by default).
The only reference to startup service at boot time is the command “systemctl enable pcsd.service”. I may missed a point somewhere but if I’m correct this configuration does not handle node restart ?
Thanks for your feedback.
Hi Alex, yes, you’re right, in my particular case the cluster nodes won’t start by default. I did this intentionally, if a cluster node fails or is restarted, I will need to run “pcs cluster start nodename” to start the cluster on it. While I could enable the services to start at boot, requiring a manual start of cluster services gives me the opportunity to do some investigation of a node failure before returning it to the cluster. I hope that this makes sense to you.
If you want your cluster nodes to start automatically, you can enable corosync/pacemaker services.
Hi Tomas. Thanks for the clarification, it make all sense for me. Furthermore after enabling corosync/pacemaker and perform reboot of a node I was able to see the following state :
node1 (online/master) > synced > node2 (online/slave)
>> shutdown of node1
node1 (offline) > node2 (online/master)
>> startup of node1
node1 (online/slave) > sync in progress > node2 (online/master)
node1 (online/slave) > synced > node2 (online/master)
Work like a charm ! Again thank for all the knowledge on this page.
You’re welcome!
Hi Tomas. i do all of the steps without any mistake and no error on pacemaker .
but i cant connect to mysql
[root@test02 ~]# mysql -h 172.17.118.76
ERROR 2003 (HY000): Can’t connect to MySQL server on ‘172.17.118.76’ (113)
when i connect to local host mysql in both of node i see deference tables on each server and not replicate
If you see different database tables, then it suggests that you have a problem with DRBD. You should start with that to see why it’s not working properly for you.
Hi Tomas,
Fist of all thx for this amazing tutorial, professional class work here :D
I have a question concerning the datadir option both in /etc/my.cnf and in the pacemaker cluster conf.
I don’t understand why you are setting it to /var/lib/mysql.
By doing so is the database (tables, datas …) replicated accross both nodes ?
I guess it is but it just seems weird to me so I prefer to ask before setting it up.
I’m sorry if you have already answered this question before but english isn’t my native and I’m sometimes struggling when I read comments.
Thanks in advance !
Okay tomas please ignore my dumb question, I just noticed the filesytem configuration in pacemaker, pointing to /var/lib/mysql.
Anyway thx for your work again !
I’m glad that you figured it out, and you’re welcome!
Is it possible to configure HA MySQL with shared storage?
If so, could you tell me how?
It’s possible, you can use GFS and iSCSI. Take a look here.
Very Nice Tutorial..
We have four nodes cluster DC (1 Master + 1 Slave) and DR (2 Slave), Now we want to restrict Master role to be available in only DC nodes, So we are planning to block MariaDB cluster resources for DR nodes.
Could you please let us know, how we can block master role for particular nodes ?
Thank you! Please refer to product documentation for how to implement the configuration that you require.
Why did you choose for DRBD while MariaDB/MySQL has a replication feature? I’m trying to get it working without DRBD, but the resource-agent that should be used for pure-replication with MariaDB doesn’t corporate well.
My problem in some more detail: https://github.com/ClusterLabs/resource-agents/issues/1441
So my question is; why didn’t you use that resource agent? And if you have used it before, could you maybe give some feedback? Thanks.
I agree, there are different ways you can achieve HA. My setup was using DRBD because I found MySQL replication geetting out of sync. With DRBD the odds for nodes running out of sync are close to zero and usually caused by bugs rather than limitations.
Hi, Thank you very much for this tutorial great job
I do have a question if you have the time to answer
in my case I’m working with Ubuntu and everything is up and fine with all the steps u cleared in the tutorial, but when i create the filesystem resource for some reason all the files required for the mysql under the /var/lib/mysql will move from the active node to the standby node and thus when i create the mysql resource the database fail to start as it can’t locate the files needed.
please any help in this matter and I would be very thankful.
I don’t have a Ubuntu environment to test, but I don’t think I had this issue on CentOS. Check the logs to see if there is anything that would point you in the right direction.
After many trials and errors, DB HA was successfully completed with pacemaker and Drbd. Thank you so much!!
You’re welcome!
Hi again, thank you for your reply
so I worked out and now all resources are up and running, still on problem occur when fail over:
the filesystem when moving to the passive node all the files will change ownership to numbers, when i search the problem found the cause is “mysql master-slave inconsistent”,do you have this problem before, there a way to solve this while resources are up?
Files always have a user identifier (UID) number. If you don’t see a username then it suggests that a user with that UID does not exits. In fact, you can change ownership of a file without having to create a user.
Is it possible that you don’t have MySQL installed on the other node? Or perhaps the mysql user does not exist?
thanks for your reply,
It turns out the mysql user on the 2 cluster node have different UID and GID on each node, and that were the inconsistent comes from; fixed it and now every thing is running as it should
many thanks to you for your great tutorial.
I thought that might be the case. Glad to hear you fixed it.
Hello,
Anyone know to why I am getting below error while creating mysql resource using pcs?
[root@testbox1 ~]# pcs resource create MySQL_ser ocf:heartbeat:mysql config=”/etc/my.cnf”
Error: Agent ‘ocf:heartbeat:mysql’ is not installed or does not provide valid metadata: Metadata query for ocf:heartbeat:mysql failed: Input/output error, use –force to override
Have you installed the Linux cluster resource agent for MySQL on all of the cluster nodes?
Hi – great turtorial – many thanks.
Im testing it out on a copuiple of virtal machines in virtualbox. I have a couple of queries however as things dont quite seem to be working quite right (which is clearly me! ). I’Il add I’ve no history or experience with pacemaker and corosync at all so have literally just cut and pasted the above with the exceptions of the system names (and using front end NICs only, no back ends) and obviously different IPs. I’ve picked a VIP on the same /24 subnet. Im also using mysql-community-server (as that is what our production servers use eslewhere) rather than mariadb
Everything installs apparently cleanly. For mysql_secure_installation I as standard answer “no” to external root access
>> Normally, root should only be allowed to connect from
>> ‘localhost’. This ensures that someone cannot guess at
>> the root password from the network.
>> Disallow root login remotely? (Press y|Y for Yes, any other key for No) : y
>> Success.
.
Once however all the commands above are run, I cant connect to the mysql database at all, not even by telnet
>> # telnet 192.168.56.200 3306
>> Trying 192.168.56.200…
>> telnet: connect to address 192.168.56.200: Connection refused
and
>> # mysql -uroot -p
>> Enter password:
>> ERROR 1045 (28000): Access denied for user ‘root’@’localhost’ (using password: YES)
nor by
>> # mysql -h 192.168.56.110 -uroot -p [ .110 is the IP of the master ]
>> Enter password:
>> ERROR 1130 (HY000): Host ‘pcmk01’ is not allowed to connect to this MySQL server
nor by
>> # mysql -h localhost -u root -p
>> Enter password:
>> ERROR 1045 (28000): Access denied for user ‘root’@’localhost’ (using password: YES)
So I dont know how I can now connect to the mysqld instance to begin development etc .
Further to that, I also notice when I restart/reboot a server(s) – pcs doesnt start.
>> # pcs status
>> Error: cluster is not currently running on this node
Again – I must presumably have not understood something properly.
Anybody have any hints please?
regards
Ian
PS I’m happy to post my notes of each step Ive taken – but it ends up being rather long as you may understand, so I’ll post it separately so as not to clag up my intial post
Hi, thanks for your feedback.
Let’s clarify a couple of things first as pacemaker clustering can get fairly complicated, and there will be issues with different versions: are you using CentOS 7.2 with MariaDB 5.5 and DRBD 8.4? If you aren’t, then my suggestion is to use those version to make sure that you can get the cluster up. Once you are in that position, you can upgrade software components.
OK… Ill try with mariadb. But for stuff outside my control Im gonna have to get it working with community mysql 5.7 sometime :-) And I suspect with Centos 8 sooner rather than later
cheers
ian
ooo – just to check – which mysql_secure_installation responses shoud be used for the above tutorial?
cheers
ian
Sure, this is what I used:
# mysql_secure_installation NOTE: RUNNING ALL PARTS OF THIS SCRIPT IS RECOMMENDED FOR ALL MariaDB SERVERS IN PRODUCTION USE! PLEASE READ EACH STEP CAREFULLY! In order to log into MariaDB to secure it, we'll need the current password for the root user. If you've just installed MariaDB, and you haven't set the root password yet, the password will be blank, so you should just press enter here. Enter current password for root (enter for none): OK, successfully used password, moving on... Setting the root password ensures that nobody can log into the MariaDB root user without the proper authorisation. Set root password? [Y/n] Y New password: NOTAREALPASSWORD Re-enter new password: NOTAREALPASSWORD Password updated successfully! Reloading privilege tables.. ... Success! By default, a MariaDB installation has an anonymous user, allowing anyone to log into MariaDB without having to have a user account created for them. This is intended only for testing, and to make the installation go a bit smoother. You should remove them before moving into a production environment. Remove anonymous users? [Y/n] Y ... Success! Normally, root should only be allowed to connect from 'localhost'. This ensures that someone cannot guess at the root password from the network. Disallow root login remotely? [Y/n] Y ... Success! By default, MariaDB comes with a database named 'test' that anyone can access. This is also intended only for testing, and should be removed before moving into a production environment. Remove test database and access to it? [Y/n] Y - Dropping test database... ... Success! - Removing privileges on test database... ... Success! Reloading the privilege tables will ensure that all changes made so far will take effect immediately. Reload privilege tables now? [Y/n] Y ... Success! Cleaning up... All done! If you've completed all of the above steps, your MariaDB installation should now be secure. Thanks for using MariaDB!Connect to MySQL server:
At this point you should set up users that can connect to the MySQL server on the VIP address etc.
OK – trying again with mariadb as the turoial.
1) # drbdadm create-md mysql01
modinfo: ERROR: Module drbd not found.
rebooted the server, then it was OK.
2) ]# pcs cluster cib clust_cfg
Error: unable to get cib
to get this working I then had to run
pcs cluster start –all
I guess this is because I had rebooted the server previously in order to get the module loaded into kernel ? And post reboot that pcs cluster start –all hadnt been run in any startup etc .
3) and finally, drum roll etc…
on teghs erver that I set everything up on as “master”
[root@pcmk01 ~]# pcs status
Cluster name: mysql_cluster
Stack: corosync
Current DC: pcmk02 (version 1.1.23-1.el7_9.1-9acf116022) – partition with quorum
Last updated: Tue Jul 6 15:41:10 2021
Last change: Tue Jul 6 15:33:47 2021 by root via cibadmin on pcmk01
2 nodes configured
5 resource instances configured
Online: [ pcmk01 pcmk02 ]
Full list of resources:
Master/Slave Set: MySQLClone01 [mysql_data01]
Masters: [ pcmk02 ]
Slaves: [ pcmk01 ]
mysql_fs01 (ocf::heartbeat:Filesystem): Started pcmk02
mysql_service01 (ocf::heartbeat:mysql): Started pcmk02
mysql_VIP01 (ocf::heartbeat:IPaddr2): Started pcmk02
Failed Resource Actions:
* mysql_VIP01_start_0 on pcmk01 ‘unknown error’ (1): call=27, status=complete, exitreason='[findif] failed’,
last-rc-change=’Tue Jul 6 15:38:07 2021′, queued=0ms, exec=1054ms
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabled
and i see on pkmc02 that /var/lib/mysql is mounted as expected, there is a mysql instance running on port 3306, I can successfully telnet to 3306 on the VIP and connect…
but I cannot still connect via mysql -uroot -p with any -h setting tried (VIP, master IP, localhost, none etc)
cheers
ian
Have you created a MySQL user for your application that can connect on the VIP address? When you run
mysql_secure_installation, it will ask you to set your root account password. At that point you should connect to the MySQL server as the root user, and set any other user, e.g. root@VIP, that you intend to you with your application.and to confirm
CentOS Linux release 7.3.1611
mysqld 5.5.68-MariaDB
drbd84
riii…iii…ggg…ht…
so you are saying – once the cluster is created with the VIP etc the root account can no longer be used – only pre created accounts thate xist before thec luster is created then work afterwards?
So how does one adminsiter the mysql instance afterwards – adding new users, schemas, grants etc – the stuff one would need a root account for?
cheers
ian
I don’t know what’s your experience with MySQL and how much work have you done with it, but there is no generic root user on MySQL. Saying “the root user” is ambiguous. Each root user is normally tied to a host that it can connect from. For example, user “root@localhost” is not the same user as user “root@pckm01” or “[email protected]”. These are three different users, and they can all have different permissions and passwords.
I didn’t go into details here because the article was about setting up the pacemaker cluster. A level of familiarity with MySQL was expected (or so was my thinking at the time of writing anyway). You’d normally spin up a MySQL instance, set a password for root@localhost using mysql_secure_installation, then log into the database as that user, and create any other user(s) that you will need for administration. I hope this clarifies things.
yes you are correct :-)
But given a root @localhost account works before the cluster, it doesnt work after the cluster. Even when one is on the amster ie on localhost.
I can see why root@VIP doesnt work – although when mysql_secure_installation is answered to NOT remove root access form anywhere etc that option seems to disappear after clustering.
but why does root@localhost not work after the cluster ?
MySQL service is managed by pacemaker and runs on a VIP (not localhost).
further to my post/query above, awaiting moderation, my notes on the steps I took.
I should also have added selinux is disabled and there is no firewalld/iptables etc. We also use xfs rather than ext4 in house.
Install Pacemaker and Corosync
yum install -y pcs
yum install -y policycoreutils-python
echo “passwd” | passwd hacluster –stdin
systemctl start pcsd.service
systemctl enable pcsd.service
Configure Corosync
[pcmk01]# pcs cluster auth pcmk01 pcmk02 -u hacluster -p passwd
[pcmk01]# pcs cluster setup –name mysql_cluster pcmk01 pcmk02
[pcmk01]# pcs cluster start –all
Install DRBD and Mysql
rpm –import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org
rpm -Uvh http://www.elrepo.org/elrepo-release-7.0-2.el7.elrepo.noarch.rpm
yum install -y kmod-drbd84 drbd84-utils
modprobe drbd
LVM Volume for DRBD
pvcreate /dev/sdb
vgcreate vg_centos7 /dev/sdb
lvcreate –name lv_drbd -l100%FREE vg_centos7
cat </etc/drbd.d/mysql01.res
resource mysql01 {
protocol C;
meta-disk internal;
device /dev/drbd0;
disk /dev/vg_centos7/lv_drbd;
handlers {
split-brain “/usr/lib/drbd/notify-split-brain.sh root”;
}
net {
allow-two-primaries no;
after-sb-0pri discard-zero-changes;
after-sb-1pri discard-secondary;
after-sb-2pri disconnect;
rr-conflict disconnect;
}
disk {
on-io-error detach;
}
syncer {
verify-alg sha1;
}
on pcmk01 {
address 192.168.56.106:7789;
}
on pcmk02 {
address 192.168.56.110:7789;
}
}
EOL
drbdadm create-md mysql01
systemctl start drbd
systemctl enable drbd
drbdadm up mysql01
[pcmk01]# drbdadm primary –force mysql01
[pcmk01]# drbd-overview
[pcmk01]# mkfs.xfs -L drbd /dev/drbd0
[pcmk01]# mount /dev/drbd0 /mnt
INSTALL MYSQL on all
yum install wget -y
wget https://dev.mysql.com/get/mysql57-community-release-el7-9.noarch.rpm
rpm -ivh mysql57-community-release-el7-9.noarch.rpm
yum install mysql-server -y
systemctl start mysqld
systemctl status mysqld
systemctl enable mysqld
grep ‘temporary password’ /var/log/mysqld.log
mysql_secure_installation (disable root login except for localhost)
systemctl disable mysqld.service
[pcmk01]# systemctl start mysqld.service
[pcmk01]# mysql_install_db –datadir=/mnt –user=mysql
[pcmk01] edit /root/.mysql_secret and update to what the root password was set to previously in
mysql_secure_installation
[pcmk01]# mysql_secure_installation
[pcmk01]# umount /mnt
[pcmk01]# systemctl stop mysqld
(both) set up my.cnf
cat < /etc/my.cnf
[mysqld]
symbolic-links=0
bind_address = 0.0.0.0
datadir = /var/lib/mysql
pid_file = /var/run/mysqldb/mysqld.pid
socket = /var/run/mysqldb/mysqld.sock
[mysqld_safe]
bind_address = 0.0.0.0
datadir = /var/lib/mysql
pid_file = /var/run/mysqldb/mysqld.pid
socket = /var/run/mysqldb/mysqld.sock
!includedir /etc/my.cnf.d
EOL
Configure Pacemaker Cluster
[pcmk01]# pcs cluster cib clust_cfg
(if fails run pcs cluster start –all )
[pcmk01]# pcs -f clust_cfg property set stonith-enabled=false
[pcmk01]# pcs -f clust_cfg property set no-quorum-policy=ignore
[pcmk01]# pcs -f clust_cfg resource defaults resource-stickiness=200
[pcmk01]# pcs -f clust_cfg resource create mysql_data01 ocf:linbit:drbd drbd_resource=mysql01 op monitor interval=30s
[pcmk01]# pcs -f clust_cfg resource master MySQLClone01 mysql_data01 master-max=1 master-node-max=1 clone-max=2 clone-node-max=1 notify=true
[pcmk01]# pcs -f clust_cfg resource create mysql_fs01 Filesystem device=”/dev/drbd0″ directory=”/var/lib/mysql” fstype=”xfs”
[pcmk01]# pcs -f clust_cfg constraint colocation add mysql_fs01 with MySQLClone01 INFINITY with-rsc-role=Master
[pcmk01]# pcs -f clust_cfg constraint order promote MySQLClone01 then start mysql_fs01
[pcmk01]# pcs -f clust_cfg resource create mysql_service01 ocf:heartbeat:mysql \
binary=”/usr/sbin/mysqld” \
config=”/etc/my.cnf” \
datadir=”/var/lib/mysql” \
pid=”/var/lib/mysql/mysql.pid” \
socket=”/var/lib/mysql/mysql.sock” \
additional_parameters=”–bind-address=0.0.0.0″ \
op start timeout=60s \
op stop timeout=60s \
op monitor interval=20s timeout=30s
[pcmk01]# pcs -f clust_cfg constraint colocation add mysql_service01 with mysql_fs01 INFINITY
[pcmk01]# pcs -f clust_cfg constraint order mysql_fs01 then mysql_service01
===
[pcmk01]# pcs -f clust_cfg resource create mysql_VIP01 ocf:heartbeat:IPaddr2 ip=192.168.56.200 cidr_netmask=32 op monitor interval=30s
[pcmk01]# pcs -f clust_cfg constraint <<< run
[pcmk01]# pcs -f clust_cfg resource show
[pcmk01]# pcs cluster cib-push clust_cfg <<< run
[pcmk01]# pcs status
TEST service
telnet 192.168.56.200 3306
Ok – Ive been round the block again and again since the above.
CentOS Linux release 7.3.1611 (Core)
On a 192.168.56.0/24 network
192.168.56.101 pcmk01 pcmk01-cr
192.168.56.106 pcmk02 pcmk02-cr
192.168.56.200 pcmkvip
I have done all the above as written except for
*the IPs as above
*no secondary network for the heartbeat type stuff so front end used.
* I also set up grants for root on the three hostnames and also all three IPs “belt and braces” before creating the mysqldb on /mnt as per above.
* the /etc/my.cnf as above does not work. mariadb starts ok but refuses all entry. reinstate the default vanilla my.cnf and all is good. Ive used a my.cnf from a server that this (if I ever can make it work anyway) will replace. access good as expected – and also
* root access from both servers was tested absolutely fine, and also on a system created with the vip address purely for testing.
Summary : up until the beginning of the cluster commands all access are as expected and needed.
But…
Once the “Configure Pacemaker Cluster” section is completed access is now unavailable.
[root@pcmk02 ~]# mysql -h192.168.56.200 -uroot -p
Enter password:
ERROR 1130 (HY000): Host ‘pcmkvip’ is not allowed to connect to this MariaDB server
[root@pcmk02 ~]# mysql -h192.168.56.106 -uroot -p
Enter password:
ERROR 1130 (HY000): Host ‘pcmk02’ is not allowed to connect to this MariaDB server
[root@pcmk02 ~]#
pcs status gives this
[root@pcmk02 ~]# pcs status
Cluster name: mysql_cluster
Stack: corosync
Current DC: pcmk01-cr (version 1.1.23-1.el7_9.1-9acf116022) – partition with quorum
Last updated: Fri Jul 16 15:11:54 2021
Last change: Fri Jul 16 14:57:35 2021 by root via cibadmin on pcmk01-cr
2 nodes configured
5 resource instances configured
Online: [ pcmk01-cr pcmk02-cr ]
Full list of resources:
Master/Slave Set: MySQLClone01 [mysql_data01]
Masters: [ pcmk02-cr ]
Slaves: [ pcmk01-cr ]
mysql_fs01 (ocf::heartbeat:Filesystem): Started pcmk02-cr
mysql_service01 (ocf::heartbeat:mysql): Started pcmk02-cr
mysql_VIP01 (ocf::heartbeat:IPaddr2): Started pcmk02-cr
Failed Resource Actions:
* mysql_VIP01_start_0 on pcmk01-cr ‘unknown error’ (1): call=32, status=complete, exitreason='[findif] failed’,
last-rc-change=’Fri Jul 16 14:59:59 2021′, queued=4ms, exec=413ms
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabled
[root@pcmk02 ~]#
[ initially this all starts on pcmk01 – but as we see that has failed over to pcmk02 as there is some error on pcmk01
Failed Resource Actions:
* mysql_VIP01_start_0 on pcmk01-cr ‘unknown error’ (1): call=32, status=complete, exitreason='[findif] failed’,
last-rc-change=’Fri Jul 16 14:59:59 2021′, queued=4ms, exec=413ms ] <<<— VIP error
* if I reboot that secondary, whilst it is rebooting the primary pcs status shows pcmk01-cr is stopped as expected.
* when the secondary has rebooted, and i log in… pcs isnt running
[root@pcmk01 ~]# pcs status
Error: cluster is not currently running on this node
However
[root@pcmk01 ~]# systemctl status pcsd
● pcsd.service – PCS GUI and remote configuration interface
Loaded: loaded (/usr/lib/systemd/system/pcsd.service; enabled; vendor preset: disabled)
Active: active (running)
so pcsd is running. but the cluster isnt. "pcs cluster start –all " gets it running again
– so does this need some startup script or similar in order to force it to run as clearly the pacemnaker etc configuration doesnt start the cluster on reboot (buit not mentioned above )
* I halt the primary. over on the secodndary it shows that previous primary as stiopped. In a short while the previous secondary becomes the primary. All looks good – but a short while later again pcs status shows an error
Failed Resource Actions:
* mysql_VIP01_start_0 on pcmk01-cr 'unknown error' (1): call=38, status=complete, exitreason='[findif] failed',
last-rc-change='Fri Jul 16 15:23:25 2021', queued=0ms, exec=88ms
It also shwos
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabled
I am able to ping that VIP address though so who knows what is going on.
* the system that was halted is powered up again. pcs status again remarks that the cluster is not running on that node. I run " pcs cluster start –all" again on the primary (wth the disabled service as above) and that now allows the restarted now secondary to be able to run pcs status.
At this stage corosync and pacemaker are both still displaying at active/disabled.
It swaps back to the newly restarted server which becomes primary/master
And of course I cannot connnect to mysql – which is running on the new primary/master 9recently rebooted system).
And that VIP error in pcs status remains
I am now desprately trying to find a solution. If anyone has a way foerward with this please jump in.
Do these MySQL users exist: root@pcmkvip and root@pcmk02? The error says that MySQL does not allow root to connect from either of these hosts.
Success!
Got there in the end. not tiotally sure what was happening but i foudn after the cluster set up my running mysql had lost all the grants it had been given before the clustering. Anyway, mysql_secure_isntallatiion re-run and away we went. Cracking.
One odd thing i am experiencing is this in pcs status.
Failed Resource Actions:
* mysql_VIP01_start_0 on pcmk01-cr ‘unknown error’ (1): call=36, status=complete, exitreason='[findif] failed’,
last-rc-change=’Mon Jul 19 14:33:55 2021′, queued=4ms, exec=185ms
if pcmk02 is up and cluster running it will always become master.
But if I brings pcmk02-cr cluster down, pcmk01 gets promoted and it all works – though the error remains.
The only way to get rid of the error seems to reboot but the error returns once pcmk01 becomes slave.
Anyone any ideas?
Did you set up your MySQL server on DRBD, or on a local filesystem? In case of the latter, it would explain why the grants were missing.
Feel free to remove all my comments/queries above as they are just cludging the place up :-0
Right – Im there… almost.
Got everything installed and with grants that all work.
initial setup is all good
[root@pcmk01 ~]# pcs status
Cluster name: mysql_cluster
Stack: corosync
Current DC: pcmk02 (version 1.1.23-1.el7_9.1-9acf116022) – partition with quorum
Last updated: Tue Jul 27 19:11:50 2021
Last change: Tue Jul 27 19:05:38 2021 by root via cibadmin on pcmk01
2 nodes configured
5 resource instances configured
Online: [ pcmk01 pcmk02 ]
Full list of resources:
Master/Slave Set: MySQLClone01 [mysql_data01]
Masters: [ pcmk01 ]
Slaves: [ pcmk02 ]
mysql_fs01 (ocf::heartbeat:Filesystem): Started pcmk01
mysql_service01 (ocf::heartbeat:mysql): Started pcmk01
mysql_VIP01 (ocf::heartbeat:IPaddr2): Started pcmk01
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
But… If I test pcmk01 (initial master) being down/offline with “pcs clusrter stop pcmk01” – the FS and musqld and VIP never come up on pcmk02 (former slave)
[root@pcmk02 ~]# pcs status
Cluster name: mysql_cluster
Stack: corosync
Current DC: pcmk02 (version 1.1.23-1.el7_9.1-9acf116022) – partition WITHOUT quorum
Last updated: Tue Jul 27 19:08:57 2021
Last change: Tue Jul 27 19:05:38 2021 by root via cibadmin on pcmk01
2 nodes configured
5 resource instances configured
Online: [ pcmk02 ]
OFFLINE: [ pcmk01 ]
Full list of resources:
Master/Slave Set: MySQLClone01 [mysql_data01]
Slaves: [ pcmk02 ]
Stopped: [ pcmk01 ]
mysql_fs01 (ocf::heartbeat:Filesystem): Stopped
mysql_service01 (ocf::heartbeat:mysql): Stopped
mysql_VIP01 (ocf::heartbeat:IPaddr2): Stopped
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
If I inspect /proc/drbd before and after I halt/stop pcmk01 (initial master)
I see firstly
01: 0: cs:SyncSource ro:Primary/Secondary
02: 0: cs:SyncTarget ro:Secondary/Primary
after i halt/stop pcmk01 I see
02: 0: cs:WFConnection ro:Secondary/Unknown
presumably of course becazsue the clustering hasnt done its stuff…
Im so close… anyboduy any hints as to what Ive got horribly wrong?
rather than second guess and provide shed loads of data/info as to what i did etc etc etc – all the above commands in the how-to for the clustering is done, drbd is set up the same (caveats over Ip addresses obviously)
welll … wierd. That was at 1917 yesterday. At 1300 today … it all works.
Hmmm.
I guess i got theer in the end… though I’ve now no idea why it suddenly works when it didnt before!
Many thanks for the pointers provided above – all greatly apprecitaed.
Just hope I cz\n implement this is real time on prod now :-)
cheers
Ian
Hi Ian, thanks for the update, I’m glad you got it working in the end!
Thanks Lisenet!